

今回から数回に分けて、Dockerで環境構築、Twitter機能の一つであるTwitterアナリティクスのデータを用いて、jupyterlabにてPythonによる分析方法を記載していきます。
本記事を読むと、
- 自分でTwitterアナリティクスの分析ができる
- 分析用のサンプルコード(Python)を使用できる
- Dockerでコンテナ内の環境構築ができる(Anaconda)
ので、ぜひ最後いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでいただけると幸いです。それではやっていましょう!
▼ Contents
1. TwitterアナリティクスからCSVデータのエクスポートする
分析のもととなる自分のTwitterデータをダウンロードしましょう。
以下のサイトにダウンロード方法の詳細およびCSVの文字化けを修正する方法がありますので、ご参考にしていただけると幸いです。
TwitterアナリティクスからCSVデータをエクスポートする方法(Mac)
なお、ダウンロードするデータは「By tweet」にしておくと、ひとつのTweetごとに分析ができるのでおすすめです。
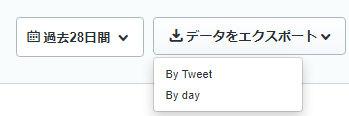
WindowsでCSVの文字化けを修正する方法はこちらのリンクが参考になります
Twitterアナリティクスのcsvデータの文字化けを解消する方法(Windows版)
2. Dockerによる環境構築
今回はDockerにてAnacondaをインストールして、Anaconda内にあるJupyterlabを使用していきます。使用環境概要は以下です。
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
フォルダー構成は以下です。先程ダウンロードしたデータは、”data”フォルダに格納しておきましょう。
.
|-- docker-compose.yml
`-- python_app
|-- Dockerfile
`-- work
|-- Twitter_analytics.ipynb
`-- data
`-- tweet_activity_metrics_XXXX_YYYYMMDD_YYYYMMDD_ja.csv
Dockerfileは以下のようにして、AnacondaをDockerコンテナ内に用意します。
#Dockerfile
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y \
sudo \
wget \
vim
#Anacondaのインストール
WORKDIR /opt
RUN wget https://repo.continuum.io/archive/Anaconda3-2020.07-Linux-x86_64.sh && \
sh /opt/Anaconda3-2020.07-Linux-x86_64.sh -b -p /opt/anaconda3 && \
rm -f Anaconda3-2020.07-Linux-x86_64.sh
ENV PATH /opt/anaconda3/bin:$PATH
WORKDIR /
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]また、Docker-compose.ymlは以下のようにしています。
version: '3'
services:
app:
build:
context: ./python_app
dockerfile: Dockerfile
container_name: app
ports:
- '5551:8888'
volumes:
- '.:/work'
tty: true
stdin_open: trueそれでは、コマンドプロンプトなどを用いて、Docker-compose.ymlのあるフォルダまで移動したら、以下のコマンドを入力してコンテナを立ち上げましょう。(初期のコンテナ作成時は時間がかかります)
$ docker-compose up -d --build無事コンテナ内に環境構築できたら、ブラウザ(Chromeなど)のURLに「localhost:5551」と入力して、Jupyterlabを開いてみましょう。
3. PythonでCSVデータを読み込む
以下はJupyterlab上での動作を想定しています。
まずは必要なライブラリをインポートします。
from pathlib import Path
import pandas as pd
import datetimeそれぞれのライブラリは
- Path: CSVファイルまでのパスを取得する
- pandas: Twitterデータをデータフレームとして扱える
- datetime: Tweet時刻を時間として扱える
として使用します。まずは、CSVファイルを読み込みましょう。
TwitterアナリティクスCSVを読み込んでデータフレームにするコードは以下です。
Data_path = './data'
File_name = '*ja.csv'
csv_files = Path(Data_path).glob(File_name)
LIST = []
for file in csv_files:
df = pd.read_csv(file, encoding='CP932')
LIST.append(df)
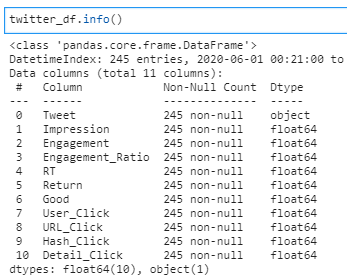
twitter_df = pd.concat(LIST)twitter_dfを見てみると以下のようなデータフレームが表示されます。

なお、encodingを”CP932″にしているのは、”utf-8″による日本語表記の読み取りでエラー発生を防ぐためです。
4. 必要データのみを抽出して、英語表記にする
twitter_dfを見ると、分析に必要のないデータが多くあることがわかると思います。そこで本記事では、「ツイート本文,時間,インプレッション,エンゲージメント,エンゲージメント率,リツイート,返信,いいね,ユーザープロフィールクリック,URLクリック数,ハッシュタグクリック,詳細クリック」の項目に絞ってデータを抽出していきます。
また、日本語表記だといろいろエラーが出そうなので、抽出したデータコラムを英語表記(Tweet, Time, Impression, Engagement, Engagement_Ratio, RT,Return, Good, User_Click, URL_Click, Hash_Click, Detail_Click)に変更します。
抽出および英語表記への変更コードは以下です。(とても簡単!)
twitter_df = twitter_df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
twitter_df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]twitter_dfを見てみると以下のように抽出されたデータコラムが英語表記になっていますね!

このあたりで、一度info()を使用してデータのTypeやNullの確認をしておくと良いと思います。
5. “Time”カラムをindexにする
データフレームのindexを時間系にすると、時系列でtwitterのデータを解析できるのでおすすめです。ここでは、”Time”のデータをindex化してみましょう。ついでに”Time”をindex化したあとに時間でソートしています。
twitter_df['Time'] = pd.to_datetime(twitter_df['Time'])
twitter_df = twitter_df.set_index('Time').sort_index()twitter_dfを見ると、indexが”Time”になっていますね。(ソートもされてます)

補足ですが、”Time”の末尾の”0000″が個人的に気になるので、apply関数で削除することが可能です。お好みで!
twitter_df['Time'] = pd.to_datetime(twitter_df['Time'].apply(lambda x: x[:-5]))6. サンプルコードとまとめ
以上の内容をまとめたサンプルコードは以下です。
""" Twitter_analytics.py """
from pathlib import Path
import pandas as pd
import datetime
Data_path = './data'
File_name = '*ja.csv'
csv_files = Path(Data_path).glob(File_name)
LIST = []
for file in csv_files:
df = pd.read_csv(file, encoding='CP932')
LIST.append(df)
twitter_df = pd.concat(LIST)
twitter_df = twitter_df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
twitter_df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
twitter_df['Time'] = pd.to_datetime(twitter_df['Time'].apply(lambda x: x[:-5]))
twitter_df = twitter_df.set_index('Time').sort_index()これで分析するtwitterデータの基本形が完成しました!
次回以降で、このtwitter_dfを使用していろいろ分析していきます。分析内容としては
- 時系列分析
- グラフによる考察
- 評価基準の設定およびその可視化
などを予定しています。乞うご期待ください。
それでは、よいPythonライフを!!
関連する次の投稿は以下です。ご覧いただけると幸いです。






[…] [Docker, Python] Twitterアナリティクスを分析してみた(①準備編) [Docker, Python] Twitterアナリティクスを分析してみた(②時系列編) [Docker, Python] Twitterアナリティクスを分析してみた(③グラフ […]
[…] [Docker, Python] Twitterアナリティクスを分析してみた(①準備編) […]
[…] [Docker, Python] Twitterアナリティクスを分析してみた(①準備編) [Docker, Python] Twitterアナリティクスを分析してみた(②時系列編) [Docker, Python] Twitterアナリティクスを分析してみた(④数値分 […]
[…] [Docker, Python] Twitterアナリティクスを分析してみた(①準備編) […]