
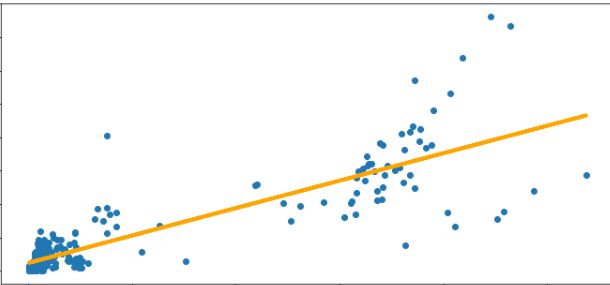
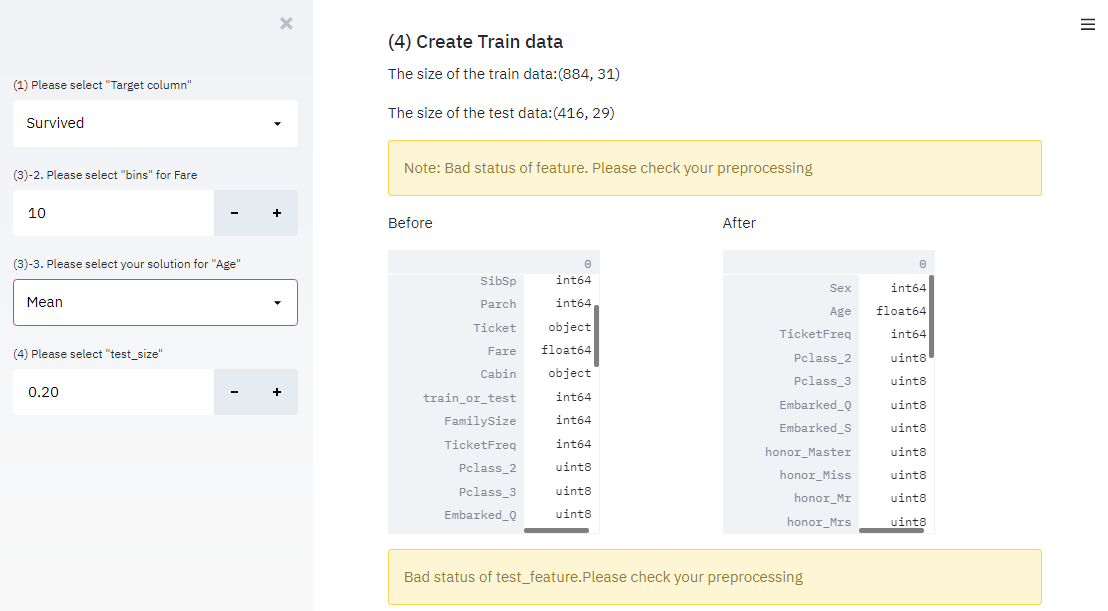
Dockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。今回は、統計学を使用して、複数の説明変数を用いた重回帰分析(sk-learnモジュール)により、’Good’の数値を予測していきたいと思います。
本記事を読むと、
- Twitterデータから重回帰分析(sk-learn)の概要がわかる
- 分析用のサンプルコード(Python)を使用できる
ので、ぜひ最後までご覧いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでいただけると幸いです。
それではやっていましょう!
▼ Contents
1. 解析用データの準備
環境構築、解析用Twitterデータの準備が終わってない方は、下記記事いただけると幸いです。
(一部、本記事では関数をclass化したりしていますが、コード自体に変更はありません)

以下の本記事内容は、Docker環境で構築したjupyter-labをベースに作成しています。予めご了承ください。使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
ファイルフォルダー構成は以下です。
.
|-- docker-compose.yml
`-- python_app
|-- Dockerfile
`-- jupyter_work
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_UserName_YYYYMMDD_YYYYMMDD_ja.csv
|-- base_analytics.py
`-- evaluation_analytics.pyDockerfileは以下のようにして、AnacondaをDockerコンテナ内に用意します。
#Dockerfile
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y \
sudo \
wget \
vim
#Anacondaのインストール
WORKDIR /opt
RUN wget https://repo.continuum.io/archive/Anaconda3-2020.07-Linux-x86_64.sh && \
sh /opt/Anaconda3-2020.07-Linux-x86_64.sh -b -p /opt/anaconda3 && \
rm -f Anaconda3-2020.07-Linux-x86_64.sh
ENV PATH /opt/anaconda3/bin:$PATH
WORKDIR /
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]また、docker-compose.ymlは以下のようにしています。
#docker-compose.yml
version: '3'
services:
app:
build:
context: ./python_app
dockerfile: Dockerfile
container_name: app
ports:
- '5551:8888'
volumes:
- '.:/work'
tty: true
stdin_open: true解析用のTwitterデータは以下のコードで取得します。
""" Twitter_analytics.ipynb """
import pandas as pd
import numpy as np
import base_analytics as ba
import evaluation_analytics as ea
""" main """
"""1.準備編 """
ba_Inst = ba.Data_path()
twitter_data_path = ba_Inst.data_path()
twitter_df = ba_Inst.data_df(twitter_data_path)
twitter_df = ba_Inst.data_en(twitter_df)
twitter_df = ba_Inst.data_time(twitter_df)
""" 5.Tweet分析編 """
string_list = ['Python', '読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
ea_Inst = ea.Eva_Inst()
ea_Inst.evaluation_string(twitter_df, string_list)
""" base_analytics.py """
"""1.準備編 """
""" 事前にtwitterデータを'ANSI'にする必要あり """
from pathlib import Path
import pandas as pd
class Data_path():
file_path = './data'
file_name = '*ja.csv'
Encode = 'CP932'
def data_path(self):
return Path(self.file_path).glob(self.file_name)
def data_df(self, files):
lists = [pd.read_csv(file, encoding=self.Encode) for file in files]
df = pd.concat(lists)
return df
def data_en(self, df):
df = df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
return df
def data_time(self, df):
df['Time'] = pd.to_datetime(df['Time'].apply(lambda x: x[:-5]))
df = df.set_index('Time').sort_index()
return df""" evaluation_analytics.py """
""" 5.Tweet分析編 """
class Eva_Inst():
def evaluation_string(self, df, string_list):
for string in string_list:
df['{}'.format(string)] = df['Tweet'].apply(lambda x: 1 if '{}'.format(string) in x else 0)
return df上記コードを実行して、’Twitter_df’を確認するとデータフレームが確認できると思います。
2. 重回帰分析の準備(説明変数と目的変数の設定)
ここでは、’複数の説明変数から目的変数’Good’数を推測する重回帰分析を実施します。まずは、下記コードを入力してみてください。
""" 7.重回帰分析編(その1) """
string_list = ['Impression', 'RT', 'Return', 'Python', \
'読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
x2 = twitter_df[string_list]
y2 = twitter_df['Good']上記コードで、説明変数と目的変数を定めました。説明変数と目的変数は、ご自身で内容を調整していただいてOKです。
3. 重回帰分析のモデル構築
さて、説明変数と目的変数のデータ準備も完了したので、早速モデルを構築していきます。次のコードを入力して、モデル構築および決定係数を算出します。
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
results = reg.fit(x2,y2)
r2 = reg.score(x2,y2).round(5)
r2なお、決定係数が不明な方は、かめさん(Twitter:@usdatascientist)ブログで決定係数R2の詳しい説明が記載されているので、ご参考にされると良いかと思います。
決定係数は,説明変数xがどれだけ目的変数yを説明しているのかを表す指標
【Pythonで学ぶ】決定係数R2を超わかりやすく解説【データサイエンス入門:統計編16】
ただし、重回帰分析は、説明変数が多いため決定係数の修正が必要となります。詳しくは以下の記事をご参考ください。
決定係数は説明変数の数が増えるほど1に近づくという性質を持っています。そのため、説明変数の数が多い場合には、この点を補正した「自由度調整済み決定係数(自由度修正済み決定係数)」を使います。自由度調整済み決定係数は次の式から求められます。nはサンプルサイズを、kは説明変数の数を表します。
27-4. 決定係数と重相関係数
$${R^2}_f = 1 – \frac{\sum_{i=1}^{n}(y_i – \hat{y_i})^2}{n – k -1} / \frac{\sum_{i=1}^{n}(y_i – \bar{y_i})^2}{n – 1}$$
そのため、以下のコードで自由度修正済み決定係数を算出しておきます。
なお、sk-learnモジュールには自由度修正済み決定係数がないため、自分で計算していきます。以下をご確認ください。
データの数は、解析するデータ数(コラム数)、変数の数は上記コードで設定した’string_list’の列数となります。
n, k = x2.shape[0], x2.shape[1]
adjusted_r2 = (1-(1-r2)*(n-1)/(n-k-1)).round(4)
adjusted_r2, r2実行すると、決定係数と自由度修正済み決定係数が算出されます。
あとは、重回帰分析の結果表を作成します。sklearnはStatusModelsのように’Summary’関数を使用できないため、以下のコードでf値やp値を算出します。
from sklearn.feature_selection import f_regression
a2 = reg.coef_.round(4)
f_values = f_regression(x2,y2)[0].round(4)
p_values = f_regression(x2,y2)[1].round(4)
reg_summary = pd.DataFrame(data = x2.columns.values, columns=['Features'])
reg_summary ['Coefficients'] = a2
reg_summary ['f-values'] = f_values
reg_summary ['p-values'] = p_values
reg_summaryこれで、図1のように本記事における重回帰分析のまとめ表が完成しました。

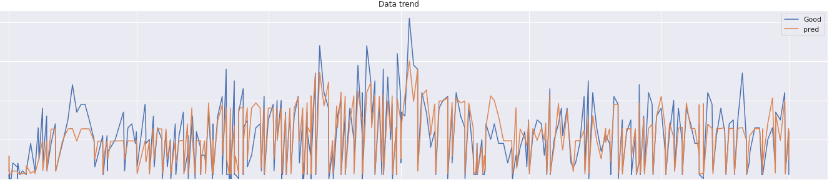
4. 重回帰分析による予測値算出
では、説明変数から’Good’数を予測してみましょう。以下のコードを入力して、予測する’Good’数のデータフレームを作成します。
今回は、説明変数リスト
[‘Impression’, ‘RT’, ‘Return’, ‘Python’, ‘読書’, ‘ブログ’, ‘筋トレ’, ‘統計’, ‘エンジニア’, ‘datascientist’]に対し、
それぞれの数値が
[2000, 1, 0, 1, 1, 1, 1, 1, 1, 0]であった場合のGood数がいくらになるかを予想しています。
new_data = pd.DataFrame(data=[[2000, 1, 0, 1, 1, 1, 1, 1, 1, 0]],columns=string_list)
reg.predict(new_data).round(4)上記コードで、’Good’数の予測値が出力されていると思います。
5. サンプルコードとまとめ
以上の内容のサンプルコードをまとめたものは以下となります。
ファイルフォルダー構成は以下です。
.
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_BaranGizagiza_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
`-- evaluation_analytics.py各ファイルは以下となります。
""" Twitter_analytics.ipynb """
import base_analytics as ba
import evaluation_analytics as ea
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import f_regression
"""1.準備編 """
ba_Inst = ba.Data_path()
twitter_data_path = ba_Inst.data_path()
twitter_df = ba_Inst.data_df(twitter_data_path)
twitter_df = ba_Inst.data_en(twitter_df)
twitter_df = ba_Inst.data_time(twitter_df)
""" 5.Tweet分析編 """
string_list = ['Python', '読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
ea_Inst = ea.Eva_Inst()
ea_Inst.evaluation_string(twitter_df, string_list)
""" 7.重回帰分析編(その1) """
string_list = ['Impression', 'RT', 'Return', 'Python', \
'読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
x2 = twitter_df[string_list]
y2 = twitter_df['Good']
reg = LinearRegression()
results = reg.fit(x2,y2)
a2 = reg.coef_.round(4)
r2 = reg.score(x2,y2).round(4)
n = x2.shape[0]
p = x2.shape[1]
adjusted_r2 = (1-(1-r2)*(n-1)/(n-p-1)).round(4)
f_values = f_regression(x2,y2)[0].round(4)
p_values = f_regression(x2,y2)[1].round(4)
reg_summary = pd.DataFrame(data = x2.columns.values, columns=['Features'])
reg_summary ['Coefficients'] = a2
reg_summary ['f-values'] = f_values
reg_summary ['p-values'] = p_values
new_data = pd.DataFrame(data=[[2000, 1, 0, 1, 1, 1, 1, 1, 1, 0]],columns=string_list)
reg.predict(new_data).round(4)以上のファイルを用意して、jupyterlab上で呼び出せば、説明変数における目的関数の予測値を算出できると思います。
次回はStatusModelsを使用した重回帰分析を実施してみます。
また、今後の記載内容としては
- 統計学とTwitterデータ(ロジスティック、クラスタリング etc.)
- Streamlitとの連携
などを予定しています。乞うご期待ください。それでは、よいPythonライフを!!
本記事に関連する過去の投稿は以下です。ご覧いただけると幸いです。


コメントを残す