

今回は、csvファイル内の特定の行(row)と列(column)のデータを抽出するloc, iloc関数を記載していきます。これをマスターすれば、大量のデータ処理が可能になるのでぜひ御覧ください。
python初心者からのバランが、実務に生かしている実例に基づいて記載してますので、実務に活かしやすいです。
▼ Contents
0. 使用環境
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Python: Version 3.7.6 (64bit)
- pandas: Version 1.0.1
1. データ解析の全体図
本記事のデータサイエンスの紹介範囲を示します。
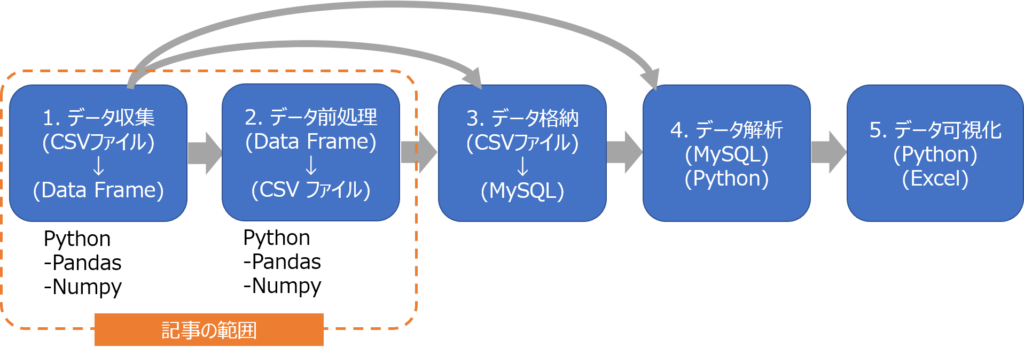
データサイエンスは主に5つのステージがあります。(図のようにステージを飛ばす場合もあります。図は一例です。)
- データ収集(データを集めて処理できる準備をする)
- データの前処理(データを格納もしくはデータを解析しやすいようにデータ配列を適切にする)
- データ格納(データを格納しておく)
- データ解析(実際のデータを用いてデータ分析・解析する)
- データ可視化(解析結果の意味がわかりやすいように可視化する)
本記事では、Pandasを用いた1. データ収集と2.データ前処理の範囲をカバーしています。
今回は”pandas”ライブラリを用いて、読み込んだ複数のCSVファイルのデータを抽出する方法を紹介します。
それでは、やっていきましょう。
2. “loc”, “iloc”によるデータ抽出
まず、csvファイルの中身のデータを抽出する関数していきましょう。
覚える関数が多くなりそうで、少し気を尻込みするかもしれませんが問題ありません。
覚える関数は2つしかなく、どちらかが使えればとりあえず大丈夫です。
バランもわからない時は同じ内容を何回も調べ直しているので、わからなくても本記事を再度読み直して使っていけば覚えていけます!
とりあえず見ていきましょう!
以下では、”example_001.csv”の中身を参考に解説します。
example_001.csv
1,11,21,31,41
2,12,22,32,42
3,13,23,33,43
4,14,24,34,44
5,15,25,35,452.1 “loc”
“loc”は、データフレーム上のロウ(行)名とコラム(列)名を指定して、指定されたデータを抽出することができます。以下の図で説明します。

ロウ(行)名とコラム(列)名それぞれ名前をつけて、抽出したいデータの行列を指定することで、データを抽出することができます。例えば、データフレーム”df”のロウ(行)名が”a”、カラム(列)名が”A”のデータを抽出したい場合の記載方法は以下となります。
df.loc["a", "A"]2.2 “iloc”
“iloc”は、データフレーム上のロウ(行)番号とコラム(列)番号を指定して、指定されたデータを抽出することができます。以下の図で説明します。
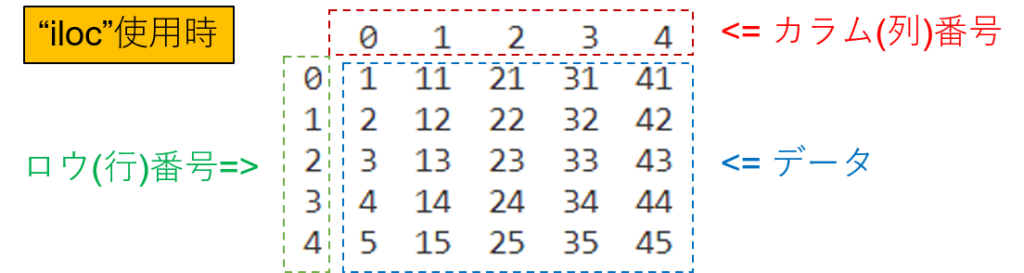
ロウ(行)番号とコラム(列)名番号それぞれはデータフレーム作成時に番号が作成されるので、抽出したいデータの行列の番号を指定することで、データを抽出することができます。
“iloc”使用時の注意点は各番号の開始番号が”0″である点です。”iloc”使用時は抽出する番号に注意すると良いです。
例えば、データフレーム”df”のロウ(行)番号が”0″、カラム(列)番号が”0″のデータを抽出したい場合の記載方法は以下となります。
df.iloc[0, 0]それでは、実際のコードを書いて確認していきましょう。
3. 実務で使えるデータ抽出方法
まず、本記事で使用するCSVが格納されているフォルダ構成例の全体図を見ていきましょう。
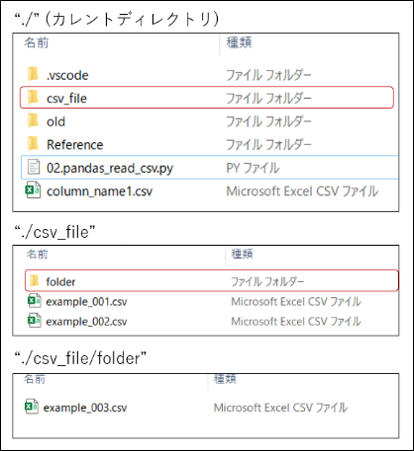
カレントディレクトリに”csv_file”フォルダを用意し、その直下に2つのCSVファイル(example_001.csv, example_002.csv)があります。さらに、”folder”があり、その直下に1つCSVファイル(example_003.csv)があります。
各CSVファイルの中身は以下です。
example_001.csv
1,11,21,31,41
2,12,22,32,42
3,13,23,33,43
4,14,24,34,44
5,15,25,35,45
example_002.csv
6,16,26,36,46
7,17,27,37,47
8,18,28,38,48
9,19,29,39,49
10,20,30,40,50
example_003.csv
101,111,121,131,141
102,112,122,132,142
103,113,123,133,143
104,114,124,134,144
105,115,125,135,145それでは複数CSVファイルのデータを抽出してみましょう。
サンプルコードは以下です。
""" 複数CSVのデータ抽出 """
import pandas as pd
from pathlib2 import Path
P = Path('./csv_file')
FILE_NAME = '**/*.csv'
CSV_FILES = P.glob(FILE_NAME)
""" ロウ(行)名 """
INDEX_NAME = ['a', 'b', 'c', 'd', 'e']
""" カラム(列)名 """
COLUMN_NAME = ('A', 'B', 'C', 'D', 'E')
def main():
for file in CSV_FILES:
""" CSVファイルデータをData Frameに変換 """
df1 = pd.read_csv(file, names=COLUMN_NAME)
""" INDEX名を与える """
df1.index = INDEX_NAME
""" データを抽出する """
df2 = df1.loc["a", "A"]
print(file)
print(df2)
print("-"*20)
if __name__ == '__main__':
main()pandasライブラリによる複数のCSV読み取り方法の基礎が不明な方は、前回の記事も合わせてお読みいただけると本記事の理解がスムーズかと思います。

本記事で重要なのは、以下のコードです。
""" データを抽出する """
df2 = df1.loc["a", "A"]このコードを変更することにより、抽出したいデータを変更することができます。
それぞれの抽出したいデータ構造を場合ワケして考えていきます。
3.1 特定の行列データを抽出したい場合
“loc”の場合は、ロウ(行)名とコラム(列)名を指定します。
“iloc”の場合は、ロウ(行)番号とコラム(列)番号を指定します。
""" データを抽出する """
df2 = df1.loc["a", "A"]
""" df2 = df1.iloc[0, 0] でも同じ結果が得られる """上記の”loc”内容でサンプルコードを実行すると以下の結果が得られます。
各CSVファイルから、[“a”, “A”]のデータが得られていますね。
csv_file\example_001.csv
1
--------------------------
csv_file\example_002.csv
6
--------------------------
csv_file\folder\example_003.csv
101
--------------------------3.2 特定の行データを抽出したい場合
“loc”の場合は、ロウ(行)名を指定します。
“iloc”の場合は、ロウ(行)番号を指定します。
""" データを抽出する """
df2 = df1.loc["a", :]
""" df2 = df1.iloc[0, :] でも同じ結果が得られる """上記の”loc”内容でサンプルコードを実行すると以下の結果が得られます。
各CSVファイルから、[“a”]の行データが得られていますね。
csv_file\example_001.csv
A 1
B 11
C 21
D 31
E 41
Name: a, dtype: int64
--------------------------
csv_file\example_002.csv
A 6
B 16
C 26
D 36
E 46
Name: a, dtype: int64
--------------------------
csv_file\folder\example_003.csv
A 101
B 111
C 121
D 131
E 141
Name: a, dtype: int64
--------------------------3.3 特定の列データを抽出したい場合
“loc”の場合は、コラム(列)名を指定します。”iloc”の場合は、コラム(列)番号を指定します。
""" データを抽出する """
df2 = df1.loc[:, "A"]
""" df2 = df1.iloc[:, 0] でも同じ結果が得られる """上記の”loc”内容でサンプルコードを実行すると以下の結果が得られます。
各CSVファイルから、[“A”]の列データが得られていますね。
csv_file\example_001.csv
a 1
b 2
c 3
d 4
e 5
Name: A, dtype: int64
--------------------------
csv_file\example_002.csv
a 6
b 7
c 8
d 9
e 10
Name: A, dtype: int64
--------------------------
csv_file\folder\example_003.csv
a 101
b 102
c 103
d 104
e 105
Name: A, dtype: int64
--------------------------3.4 特定の範囲行列データを抽出したい場合
“loc”の場合は、ロウ(行)名とコラム(列)名の範囲を指定します。”iloc”の場合は、ロウ(行)番号とコラム(列)番号も範囲を指定します。
例えば、ロウ名を”a”から”b”、コラム名を”B”から”C”の範囲を指定します。
""" データを抽出する """
df2 = df1.loc["a":"b", "B":"C"]
""" df2 = df1.iloc[0:1, 1:2] でも同じ結果が得られる """上記の”loc”内容でサンプルコードを実行すると以下の結果が得られます。
各CSVファイルから、[“a”:”b”, “B”:”C”]の範囲行列データが得られていますね。
csv_file\example_001.csv
B C
a 11 21
b 12 22
--------------------------
csv_file\example_002.csv
B C
a 16 26
b 17 27
--------------------------
csv_file\folder\example_003.csv
B C
a 111 121
b 112 122
--------------------------4. まとめ
今回の記事は、pythonによる複数csvファイルのデータを抽出する方法をまとめました。
csvファイルを一括で読み込むみ、”loc”もしくは”iloc”で特定の行列範囲のデータを抽出することができます。
つまり、データ構造が同じCSVファイルであれば、複数のデータを一括で抽出することできます。
大量の同じデータ構造を処理する際に非常に便利なので、覚えていただけると業務が捗りますね。
次回は、抽出した複数のデータを結合して、新たなcsvファイルとして保存する方法を記事にする予定です。
それでは、良いpythonライフを!






[…] 【Python入門】複数CSVのデータ抽出【初心者向け】 […]