
Dockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。前回はsk-learnで重回帰分析を行いましたが、今回はStatusModelsを使用して、複数の説明変数を用いた重回帰分析により、’Good’の数値を予測していきたいと思います。
本記事を読むと、
- Twitterデータから重回帰分析(StatusModels)の概要がわかる
- 分析用のサンプルコード(Python)を使用できる
ので、ぜひ最後までご覧いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでいただけると幸いです。
それではやっていましょう!
▼ Contents
1. 解析用データの準備
環境構築、解析用Twitterデータの準備が終わってない方は、下記記事いただけると幸いです。
(一部、本記事では関数をclass化したりしていますが、コード自体に変更はありません)

以下の本記事内容は、Docker環境で構築したjupyter-labをベースに作成しています。予めご了承ください。使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
StatsModelsモジュールがインストールされていない方は、ターミナルもしくはDockerfileからモジュールをインストールしてください。
$ pip install statsmodelsRUN pip3 install --upgrade statsmodelsファイルフォルダー構成は以下です。
.
|-- docker-compose.yml
`-- python_app
|-- Dockerfile
`-- jupyter_work
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_UserName_YYYYMMDD_YYYYMMDD_ja.csv
|-- base_analytics.py
`-- evaluation_analytics.py解析用データは以下のコードで取得します。
""" Twitter_analytics.ipynb """
import pandas as pd
import numpy as np
import base_analytics as ba
import evaluation_analytics as ea
""" main """
"""1.準備編 """
ba_Inst = ba.Data_path()
twitter_data_path = ba_Inst.data_path()
twitter_df = ba_Inst.data_df(twitter_data_path)
twitter_df = ba_Inst.data_en(twitter_df)
twitter_df = ba_Inst.data_time(twitter_df)
""" 5.Tweet分析編 """
string_list = ['Python', '読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
ea_Inst = ea.Eva_Inst()
ea_Inst.evaluation_string(twitter_df, string_list)
""" base_analytics.py """
"""1.準備編 """
""" 事前にtwitterデータを'ANSI'にする必要あり """
from pathlib import Path
import pandas as pd
class Data_path():
file_path = './data'
file_name = '*ja.csv'
Encode = 'CP932'
def data_path(self):
return Path(self.file_path).glob(self.file_name)
def data_df(self, files):
lists = [pd.read_csv(file, encoding=self.Encode) for file in files]
df = pd.concat(lists)
return df
def data_en(self, df):
df = df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
return df
def data_time(self, df):
df['Time'] = pd.to_datetime(df['Time'].apply(lambda x: x[:-5]))
df = df.set_index('Time').sort_index()
return df""" evaluation_analytics.py """
""" 5.Tweet分析編 """
class Eva_Inst():
def evaluation_string(self, df, string_list):
for string in string_list:
df['{}'.format(string)] = df['Tweet'].apply(lambda x: 1 if '{}'.format(string) in x else 0)
return df上記コードを実行して、’Twitter_df’を確認するとデータフレームが確認できると思います。
2. 重回帰分析の準備(説明変数と目的変数の設定)
ここでは、’複数の説明変数から目的変数’Good’数を推測する重回帰分析を実施します。
まずは、下記コードを入力してみてください。
""" 8.重回帰分析編(その2) """
string_list = ['Impression', 'RT', 'Return', 'Python', \
'読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
x2 = twitter_df[string_list]
y2 = twitter_df['Good']上記コードで、説明変数と目的変数を定めました。説明変数と目的変数は、ご自身で内容を調整していただいてOKです。
3. 重回帰分析のモデル構築
さて、説明変数と目的変数のデータ準備も完了したので、早速モデルを構築していきます。次のコードを入力して、分析モデル構築します。
import statsmodels.api as sm
""" 定数項(y切片)を必要とする線形回帰のモデル式ならば必須 """
X = sm.add_constant(x2)
model = sm.OLS(y2, X)
result = model.fit()これでモデル構築が作成できました。以下のコードを記載して、まとめ表を見てみましょう。
result.summary()以下のような表が作成されます。
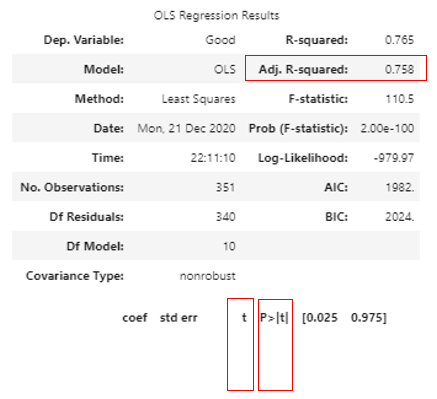
StatusModelsの良い点のひとつは、上記のようにSummary()関数でまとめ表が作成されるところですね。まとめ表から以下の3つを確認しておきましょう。
- Adj. R-squared:自由度調整済み決定係数
- t:各説明変数ごとの統計量
- p>|t|:各説明変数ごとのp値
Adj. R-squaredは、作成した分析モデルの説明精度、つまりモデルの出来をしめしており、0が最小(全く説明できない)から1(完全に説明できる)となります。
今回は0.758なのでまずまずでした。
t値とp値に関しては、各説明変数をモデルに使用してよいかの判断材料となります。
一般的に
t値が「1未満」であれば「統計学的にモデルに組み込むのは支持できない」
P>|t|が「0.05」以上であれば、有意水準を5%とした際に、p値が5%以上であれば帰無仮説を棄却せず、逆に5%未満であれば帰無仮説を棄却し、対立仮説を採用する
となります。詳しくは以下のサイトがわかりやすいです。
t: t値。係数の有意性(意味がある説明変数かどうか)を検定するための統計量。 t 値=係数の推定値/係数の標準誤差。概ね 2 より大きければ良い。
P>|t|: p 値(t 検定に基づく)。説明変数として意味の無い(係数がゼロである)確率。小さければ意味のある説明変数である(「有意」である)と判断。
単回帰分析:statsmodels OLS.summaryの各変数の意味
この結果から、「Return」が統計学的に意味がないと判断されたので、説明変数から取り除いて、もう一度分析モデルを作成します。
x3, y3 = x2.drop('Return', axis=1), twitter_df['Good']
X = sm.add_constant(x3)
model = sm.OLS(y2, X)
result = model.fit()これで、モデル構築完了です。
4. 重回帰分析による予測値算出
では、構築した分析モデルから’Good’数を予測してみましょう。
今回は以下のコードを入力して、モデルの精度がどの程度あるかグラフで確かめてみます。
以下のコードを入力してみてください。
from matplotlib import pyplot as plt
""" 構築モデルから予測値を算出 """
twitter_df['pred'] = result.predict(X)
""" 実値と予測値をグラフ化 """
fig, axes = plt.subplots(figsize=(20,5))
axes.plot(twitter_df.index, 'Good', data=twitter_df, label='Good')
axes.plot(twitter_df.index, 'pred', data=twitter_df, label='pred')
axes.set_xlabel('Date')
axes.set_ylabel('Good')
axes.set_title('Data trend')
axes.legend(loc=0)
fig.tight_layout()
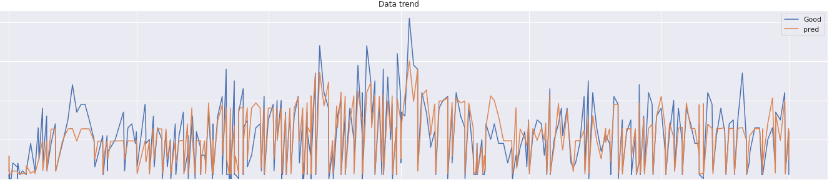
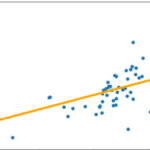
plt.plot()上記コードを入力すると、実際の’Good’数と予測した’Good’数である’pred’が表示されます。
この図からどのTweetの分析がうまく予想されているかわかると思います。
5. サンプルコードとまとめ
以上の内容のサンプルコードをまとめたものは以下となります。
""" Twitter_analytics.ipynb """
import base_analytics as ba
import evaluation_analytics as ea
import pandas as pd
import numpy as np
import statsmodels.api as sm
"""1.準備編をご参考ください """
ba_Inst = ba.Data_path()
twitter_data_path = ba_Inst.data_path()
twitter_df = ba_Inst.data_df(twitter_data_path)
twitter_df = ba_Inst.data_en(twitter_df)
twitter_df = ba_Inst.data_time(twitter_df)
""" 5.Tweet分析編をご参考ください """
string_list = ['Python', '読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
ea_Inst = ea.Eva_Inst()
ea_Inst.evaluation_string(twitter_df, string_list)
""" 8.重回帰分析編(その2) """
string_list = ['Impression', 'RT', 'Return', 'Python', \
'読書', 'ブログ', '筋トレ', '統計', 'エンジニア', 'datascientist']
x2, y2 = twitter_df[string_list], twitter_df['Good']
X = sm.add_constant(x2)
model = sm.OLS(y2, X)
result = model.fit()
x3, y3 = x2.drop('Return', axis=1), twitter_df['Good']
X = sm.add_constant(x3)
model = sm.OLS(y2, X)
result = model.fit()
twitter_df['pred'] = result.predict(X)
fig, axes = plt.subplots(figsize=(20,5))
axes.plot(twitter_df.index, 'Good', data=twitter_df, label='Good')
axes.plot(twitter_df.index, 'pred', data=twitter_df, label='pred')
axes.set_xlabel('Date')
axes.set_ylabel('Good')
axes.set_title('Data trend')
axes.legend(loc=0)
fig.tight_layout()
plt.plot()以上のファイルを用意して、jupyterlab上で呼び出せば、説明変数における目的関数の予測値がグラフ化されていると思います。
次回はsk-learnでのt値の算出方法を検討します。また、今後の記載内容としては
- Streamlitとの連携
などを予定しています。乞うご期待ください。それでは、よいPythonライフを!!
本記事に関連する過去の投稿は以下です。ご覧いただけると幸いです。



コメントを残す