

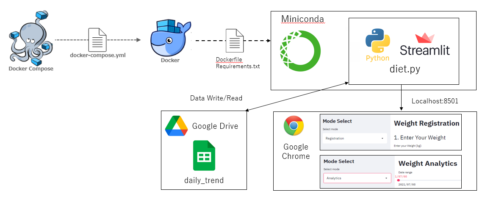
Dockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。今回から、趣旨である自身のTwitterアナリティクスのTweet文字列を分析していきます。
本記事を読むと、
- どんなTweetが高評価かわかる
- Tweet文字列を分析できる
- 分析用のサンプルコード(Python)を使用できる
ので、ぜひ最後までご覧いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでいただけると幸いです。
それではやっていましょう!
▼ Contents
1. 解析用データの準備
環境構築、解析用Twitterデータの準備が終わってない方は、下記記事いただけると幸いです。

以下の本記事内容は、Docker環境で構築したJupyterlabをベースに作成しています。予めご了承ください。
使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
ファイルフォルダー構成は以下です。
.
|-- docker-compose.yml
`-- python_app
|-- Dockerfile
`-- jupyter_work
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_UserName_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
`-- evaluation_analytics.pyDockerfileは以下のようにして、AnacondaをDockerコンテナ内に用意します。
#Dockerfile
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y \
sudo \
wget \
vim
#Anacondaのインストール
WORKDIR /opt
RUN wget https://repo.continuum.io/archive/Anaconda3-2020.07-Linux-x86_64.sh && \
sh /opt/Anaconda3-2020.07-Linux-x86_64.sh -b -p /opt/anaconda3 && \
rm -f Anaconda3-2020.07-Linux-x86_64.sh
ENV PATH /opt/anaconda3/bin:$PATH
WORKDIR /
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]また、docker-compose.ymlは以下のようにしています。
#docker-compose.yml
version: '3'
services:
app:
build:
context: ./python_app
dockerfile: Dockerfile
container_name: app
ports:
- '5551:8888'
volumes:
- '.:/work'
tty: true
stdin_open: true2. Tweetに特定文字を含んでいるか確認する
今回は、Tweetの文字を分析していくために、まずは各Tweetに特定文字が含まれているか確認します。まずは、調査したい特定文字をリスト化しましょう。
以下のコードのように調査したい文字列をリスト化してみてください。(私は[‘読書’, ‘ブログ’, ‘筋トレ’, ‘統計学’, ‘datascientist’]としました。
""" Twitter_analytics.ipynb """
""" 5.Tweet分析編 """
string_list = ['読書', 'ブログ', '筋トレ', '統計学', 'datascientist']文字列をリスト化したら、その文字列が含まれるTweetには整数の’1’を付与して、含まれない場合には整数の’0’を付与します。以下のコードを’evaluation_analytics.py’に実装してみましょう。
""" evaluation_analytics.py """
""" 5.Tweet分析編 """
def evaluation_string(df, string_list):
for string in string_list:
df['{}'.format(string)] = df['Tweet'].apply(lambda x: 1 if '{}'.format(string) in x else 0)
return dfそして、’Twitter_analytics.ipynb’で以下のコードを入力してみてください。
import evaluation_analytics as ea
""" 特定文字列の有無を1, 0で分ける """
string_list = ['読書', 'ブログ', '筋トレ', '統計学', 'datascientist']
ea.evaluation_string(twitter_df, string_list)以上のコードを入力すると、Twitterデータのカラムに各特定文字列が含まれているかを判定する列が生成されます。
以下の図1は、[‘読書’, ‘ブログ’, ‘筋トレ’, ‘統計学’, ‘datascientist’]の文字列が含まれていないです。

文字列の分類ができたところで、この文字列が各データ値に与える影響を見てみましょう。
3. Seaborn-pairplotを使用して特定文字列の効果を確認する
文字列の分類ができたので、文字列を含んだ際の効果を可視化していきます。
本記事では、Seabornのpairplotを使用します。
pairplotの詳細を知りたい方は、以下のサイトが詳しいです。
Python, pandas, seabornでペアプロット図(散布図行列)を作成
pairplotを作成するため、以下のコードを入力してみましょう。
""" evaluation_analytics.py """
def string_pairplot(df, string_list):
for string in string_list:
sns.pairplot(df[['Impression', 'Engagement', 'Engagement_Ratio', 'Good', 'User_Click', 'Detail_Click', '{}'.format(string)]],
hue='{}'.format(string),
plot_kws={'alpha':0.3},
diag_kind='hist'
)ea.string_pairplot(twitter_df, string_list)以上のコードを入力すると、各特定文字のpairplotが作成されます。
(日本語表記でhueを利用しているため、warningが出るかもしれませんが、ここでは無視します。)
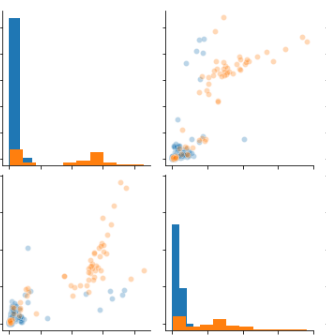
上図は、文字列’datascientist’の有無でTweetを分けた際の’Impression’と’Engagement’のpairplotを表示しています。(オレンジ色が文字列を含む、青色が文字列を含まない)
図を確認すると、明らかにオレンジ色のほうが、’Impression’と’Engagement’ともに数字が高く、頻度も多いことがわかります。
以上から、私のTweetで’Impression’と’Engagement’の数字が高いのは、文字列’datascientist’を含むTweetであることがわかります。
このようにグラフから数字を多く得ているTweetを参考にすると良さそうです。
4. サンプルコードとまとめ
以上の内容のサンプルコードをまとめたものは以下となります。
ファイルフォルダー構成は以下です。
.
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_BaranGizagiza_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
`-- evaluation_analytics.py各ファイルは以下となります。
""" Twitter_analytics.ipynb """
import data_base_analytics as da
import evaluation_analytics as ea
def main():
""" main """
"""1.準備編 """
twitter_data_path = da.data_path()
twitter_df = da.data_df(twitter_data_path)
twitter_df = da.data_en(twitter_df)
twitter_df = da.data_time(twitter_df)
""" 5.Tweet分析編 """
string_list = ['読書', 'ブログ', '筋トレ', '統計学', 'datascientist']
ea.evaluation_string(twitter_df, string_list)
ea.string_pairplot(twitter_df, string_list)""" data_base_analytics.py """
"""1.準備編 """
from pathlib import Path
import pandas as pd
Data_path = './data'
Data_file_name = '*ja.csv'
Encode = 'CP932'
def data_path():
return Path(Data_path ).glob(Data_file_name)
def data_df(file_path):
LIST = [pd.read_csv(file, encoding=Encode) for file in file_path]
df = pd.concat(LIST)
return df
def data_en(df):
df = df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
return df
def data_time(df):
df['Time'] = pd.to_datetime(df['Time'].apply(lambda x: x[:-5]))
df = df.set_index('Time').sort_index()
return df""" evaluation_analytics.py """
""" 5.Tweet分析編 """
import matplotlib.pyplot as plt
import seaborn as sns
def evaluation_string(df, string_list):
for string in string_list:
df['{}'.format(string)] = df['Tweet'].apply(lambda x: 1 if '{}'.format(string) in x else 0)
return df
def string_pairplot(df, string_list):
for string in string_list:
sns.pairplot(df[['Impression', 'Engagement', 'Engagement_Ratio', 'Good', 'User_Click', 'Detail_Click', '{}'.format(string)]],
hue='{}'.format(string),
plot_kws={'alpha':0.3},
diag_kind='hist'
)以上のファイルを用意して、jupyterlab上でmain()を呼び出せば、各特定文字列を含むTweetの数値データのpairplotを表示できると思います。
私も詰まったところが、pythonファイルを更新すると、モジュールを読み込む際は、「カーネルを再起動するか、import libを使う」必要があります。詳しくは以下のサイトに記載されているので、ご参考いただけると幸いです。
【Python】Jupyter notebookを使うときに守るべきPythonの作法2選
次回は、統計学を織り交ぜて解析をしていく予定です。
また、今後の分析内容としては
- 統計学とTwitterデータ(単回帰、重回帰、ロジスティック、クラスタリング etc.)
などを予定しています。乞うご期待ください。それでは、よいPythonライフを!!
本記事に関連する過去の投稿は以下です。ご覧いただけると幸いです。



[…] [Docker, Python] Twitterアナリティクスを分析してみた(④数値分析編) [Docker, Python] Twitterアナリティクスを分析してみた(⑤Tweet分析編) [Docker, Python] Twitterアナリティクスを分析してみた(⑥単回帰分析編) […]
[…] [Docker, Python] Twitterアナリティクスを分析してみた(⑤Tweet分析編) […]