
CSVファイルからあるデータを抽出して、Python上でリストとして扱いたいことはありませんか?
本記事は、CSVファイルからデータを抽出して、そのデータをリスト形式のデータとして利用する方法を記載しています。
本記事を読むと、”pandas”ライブラリを使用して
- CSVファイルのデータをカラム名として利用できる
- CSVファイルでカラム名を管理できる(Pythonファイルを変更する必要がない)
ができるようになります。これをマスターすれば、カラム名を簡単に変更することができるのでぜひ御覧ください。
▼ Contents
0. 使用環境
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Python: Version 3.7.6 (64bit)
- pandas: Version 1.0.1
1. データ解析の全体図
本記事のデータサイエンスの紹介範囲を示します。
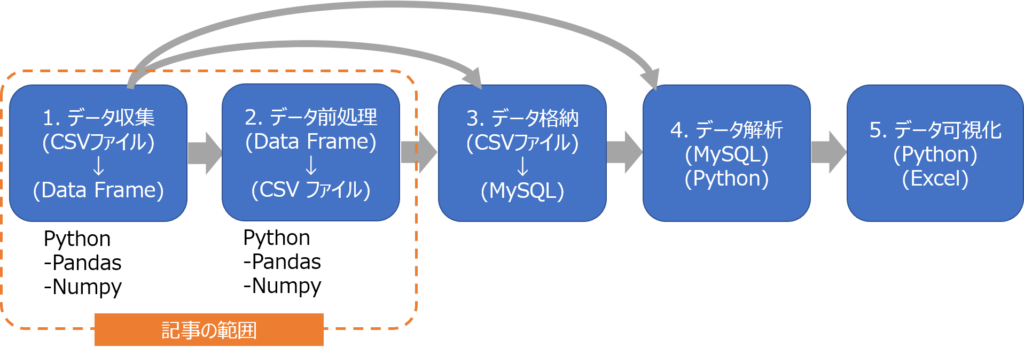
データサイエンスは主に5つのステージがあります。(図のようにステージを飛ばす場合もあります。図は一例です。)
- データ収集(データを集めて処理できる準備をする)
- データの前処理(データを格納もしくはデータを解析しやすいようにデータ配列を適切にする)
- データ格納(データを格納しておく)
- データ解析(実際のデータを用いてデータ分析・解析する)
- データ可視化(解析結果の意味がわかりやすいように可視化する)
本記事では、Pandasを用いた1. データ収集と2.データ前処理の範囲をカバーしています。
今回は”pandas”ライブラリとformat文を用いて、CSVファイルからデータを抽出して、そのデータをリスト形式として、カラム名を変更する方法を記載しています。
それでは、やっていきましょう。
2. 実務で使えるファイル名を自動変更して保存する方法
まず、本記事で使用するCSVが格納されているフォルダ構成例の全体図を見ていきましょう。今回はworkフォルダー直下にPythonファイルとカラム名用のCSVファイル”column_name1.csv”を用意しています。
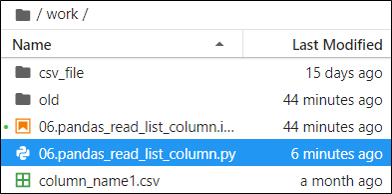
“column_name1.csv”のデータは以下のようにしています。
A, B, C, D, Eまた、Workフォルダには”csv_file”フォルダを用意し、その直下に2つのCSVファイル(example_001.csv, example_002.csv)があります。さらに、”folder”フォルダがあり、その直下にもう1つのCSVファイル(example_003.csv)があります。
それぞれのCSVファイルは以下のようにデータとなっています。
example_001.csv
1,11,21,31,41
2,12,22,32,42
3,13,23,33,43
4,14,24,34,44
5,15,25,35,45
example_002.csv
6,16,26,36,46
7,17,27,37,47
8,18,28,38,48
9,19,29,39,49
10,20,30,40,50
example_003.csv
101,111,121,131,141
102,112,122,132,142
103,113,123,133,143
104,114,124,134,144
105,115,125,135,145それではCSVファイルのデータを抽出して、カラム名として利用するためにリスト形式にします。
サンプルコードは以下です。
import pandas as pd
from pathlib2 import Path
"""
複数CSVのデータ抽出とファイル出力
"""
P = Path('/work/csv_file')
FILE_NAME = '**/*.csv'
CSV_FILES = P.glob(FILE_NAME)
COLUMN_NAMES = pd.read_csv('/work/column_name1.csv').columns.tolist()
MONTH = "2020-08"
OUTPUT = "006"
LIST = []
def main():
for name in COLUMN_NAMES:
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)
df = pd.concat(LIST, axis=1)
output_name = 'example_{0}_{1}_{2}.csv'.format(OUTPUT, MONTH, name)
df.to_csv(output_name, index=True, encoding="utf-8")
if __name__ == '__main__':
main()“pathlib”ライブラリやデータスライス方法、データ結合方法が不明な方は以下のブログを見ていただけると理解がスムーズかと思います。

今回はシンプルで、注目する箇所は一箇所です。
""" COLUMN_NAMES = ['A', 'B', 'C', 'D', 'E']と同じデータ形式 """
COLUMN_NAMES = pd.read_csv('/work/column_name1.csv').columns.tolist()前回はカラム名を最初からリスト形式で指定していましたが、今回は”Pandas”ライブラリを使用して、CSVファイルからカラム名データを抽出します。
抽出したデータをリスト形式にするには、”columns”関数でDataFrame型データをIndex化した後、”tolist()”関数でリスト化します。
この操作により、CSVファイル”column_name1.csv”に記載されているデータをカラム名として利用できます。
それでは、サンプルコードを実行してみましょう。実行すると以下のように複数のデータが出力されます。
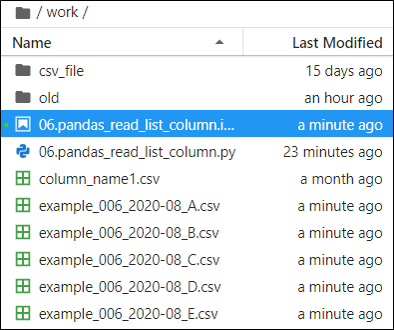
CSVファイルでカラム名を管理する場合は、”column_name1.csv”ファイルの中身を変更すれば良いです。
例えば、以下のようにカラム名を変更したい場合、”column_name1.csv”を変更します。(ファイル名は変更しない)
G, H, I ,J, K“column_name1.csv”のデータを変更したあとに、先ほどのサンプルコードを実行すると、以下のようにカラム名が変更された複数のCSVが出力されます。
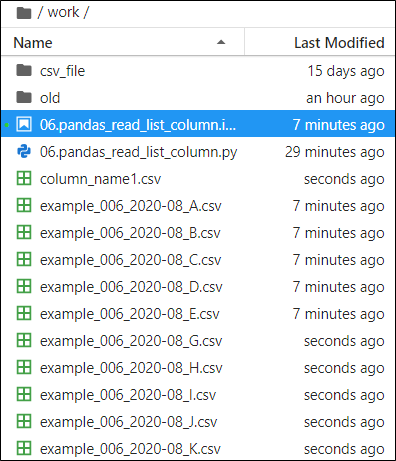
このように、CSVファイル上でカラム名を管理できるので、Pythonファイルを開くことなく、カラム名を管理できます。
また、カラム名が多い場合などでは、コピー&ペーストができるCSVで管理したほうが良い場合があるので、ぜひ使いこなしてみてください。
3. まとめ
今回の記事は、pythonによるCSVファイルのデータを抽出し、そのデータをカラム名として使用する方法をまとめました。
CSVファイル上でカラム名を管理できるので、Pythonファイルを開くことなく、カラム名を管理できます。
また、カラム名が多い場合などCSV上でコピー&ペーストができます。
次回は、長くなってきたPythonスクリプトを関数としてまとめる方法をを記事にする予定です。
それでは、良いpythonライフを!





[…] 【Python入門】CSVファイルをリスト形式で読み込む方法【初心者向き】 […]