
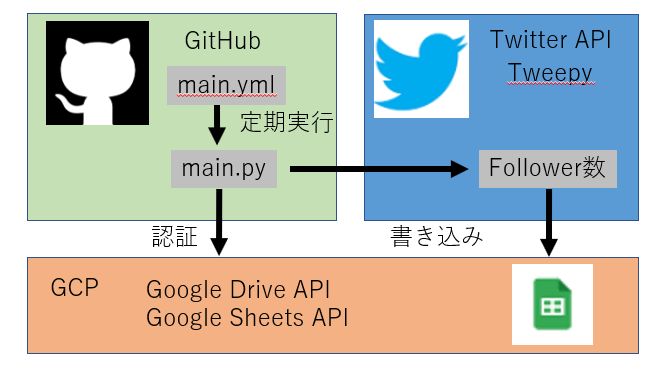
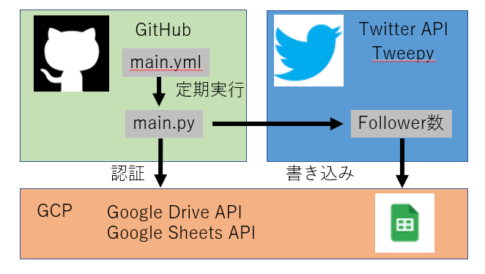
今回は、前回記事で紹介したPython+Twitter APIで取得したご自身のTwitterフォロワー数を、Google Could Platform(以下GCP)のAPIを使用して、Google Drive上のスプレッドシートに保存する方法を記載します。
GCPをはじめて使用する方や、Googleスプレッドシートを活用したい方、Twitterフォロワー数が気になる方にはおすすめの記事です。また、本記事は、自動更新のためWeb上にコードをアップしますので、テスト環境と本番環境も踏まえて、コードを記載していきます。
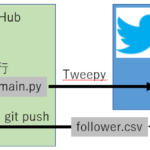
完成時の実行フローは上図のとおりです。GitとGitHubを使用するので、不明な方はこちらのブログなどを読んでいただけると理解が早いと思います。
【超入門】Github登録からGit使い方の基本まで完全解説①【初心者必見】
https://datawokagaku.com/github_register/
▼ Contents
1. 使用環境
- OS: Windows10 Pro
- Python: Version 3.8
- Tweepy: Version 3.10.0 (vver4.0以降は一部APIが削除されています。)
2. Twitter APIによるフォローワー数取得(前回記事)
Twitter APIを使用したフォロワー数の取得方法は、前回記事に記載しています。不明な方はご覧いただけると幸いです。以下では、フォロワー数を取得した状態から開始します。
3. GCP関連設定
3-1. GCP登録とプロジェクト作成
まずは、GCPを使用できるように準備します。といっても、Googleアカウントがあればすぐできます。
以下の記事がとても詳しかったのでご参考いただければと思います。本記事で最低限必要なのは、GCP内でプロジェクトを作成するところまでです。
本記事は、これからGCP(GCE)を始める人を対象とした記事になります。個人開発や学習等でGCP(GCE)を利用するにあたり、GCP(GCE)の構築手順(VMインスタンス作成〜SSH接続)と、最低限実施しておくとよいセキュリテイ対策についてまとめました。きちんと仕様を理解し、セキュリテイ対策を行った上で、安全に無料枠を利用しましょう。
これから始めるGCP(GCE) 安全に無料枠を使い倒せ
本記事では、”Twitter-GCP”というプロジェクトを作成↓として記事を続けます。以下のような画面までできましたら、次へお進みください。
3-2. GCP APIを有効にする
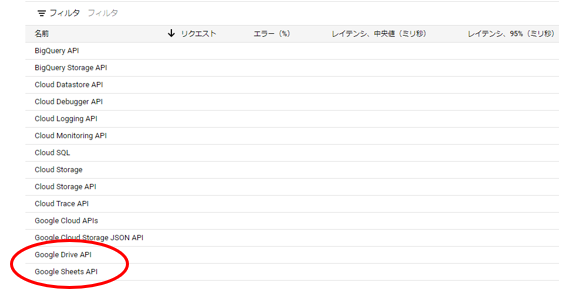
ここからは、GCP上にある2つのAPIを有効にします。有効にするAPIは以下です。
- Google Sheets API
- Google Drive API
ダッシュボード上で、”APIとサービス”をクリックします。
次に”APIとサービスの有効化”をクリックして、有効にするAPIを検索します。
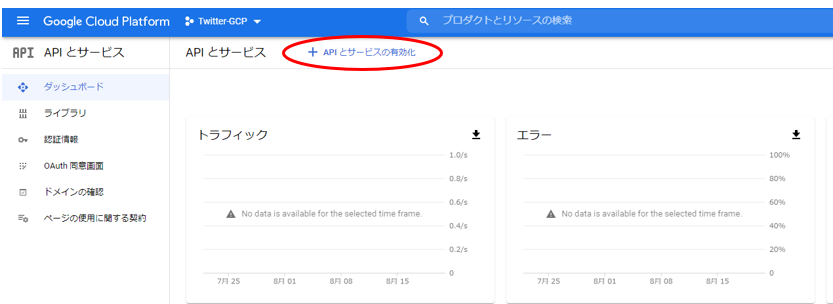
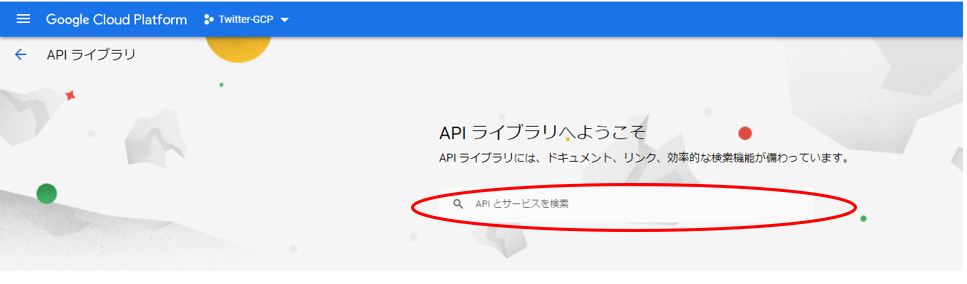
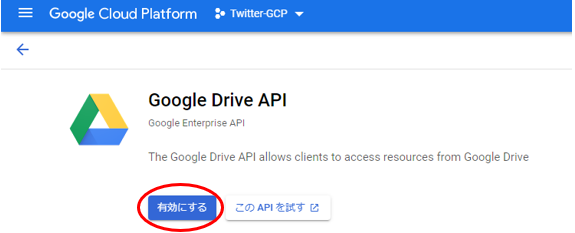
“Sheet”や”Drive”で検索すると、目的のAPIが検索されると思います。検索したAPIをクリックし、”有効にする”をクリックします。
2つのAPIを有効にしたら、”APIとサービス”のダッシュボードに戻り、APIが有効になっていることを確認します。
これでAPIの有効化は完了です。次はAPIを使用するための認証キーを取得します。
3-3. 認証キー(JSONファイル)を入手する
ここでは有効にしたAPIをPythonで使用するための認証キーを取得します。まず、”APIとサービス”のダッシュボードから、”認証情報”をクリックします。そして、”認証情報を作成”をクリックします。
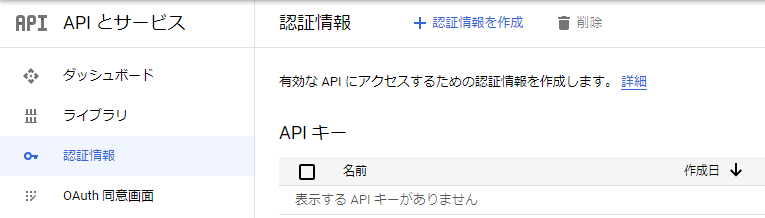
そうすると、認証情報種類の選択画面が出てきます。ここでは”サービスアカウント”を選択します。
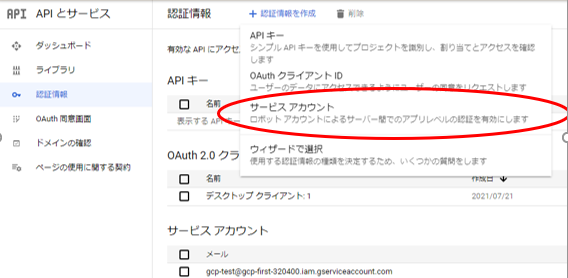
”サービスアカウントの詳細”の画面に移ります。この画面では、サービスアカウトン名を決定します。ここでは”twitter-gcp”としました。お好みでOKです。説明欄は任意です。
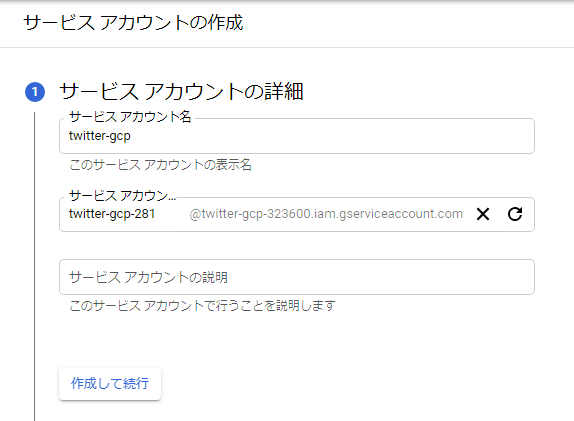
その後の、
- このサービス アカウントにプロジェクトへのアクセスを許可する
- ユーザーにこのサービス アカウントへのアクセスを許可
はここでは必要ないため、”続行”をクリックし、最後に”完了”をクリックします。そうするとダッシュボード上に、サービスアカウントが作成されますのでクリックします。
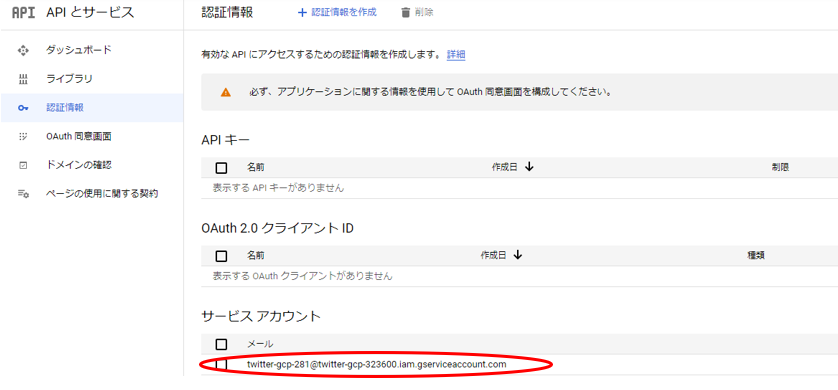
“IAMと管理”のダッシュボードに移ります。”キー”=>”鍵を追加”=>”新しい鍵を作成”をクリックします。
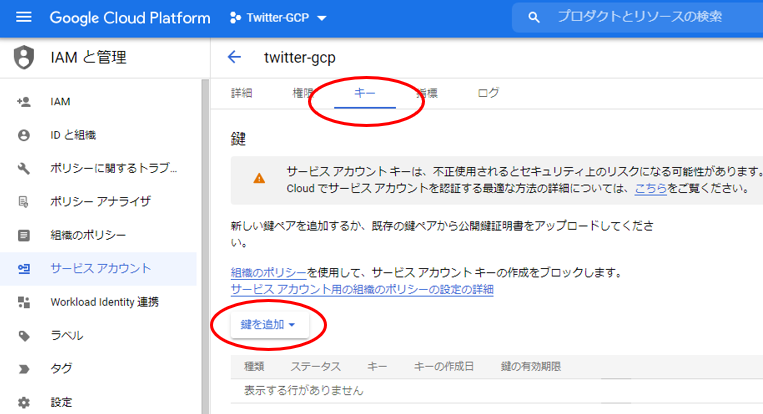
秘密鍵の作成画面に移るので、”JSON”形式の鍵を作成します。

“作成”ボタンを押すと、ローカルPCにJSOnファイルがダウンロードされるので、保管しておいてください。次章以降で使用します。
なお、ファイル名が長いので’gcp_secret.json’に変更します。(ファイル名はお好みでOKです)

JSONファイルの中身は、重要な情報ですので、他の人に見せないようにしましょう。
これでAPIを使用できる準備が整いましました(長い。。。)

そろそろコード書きたい
3-4. データ保存用のスプレッドシートを準備する
続いて、データ格納用のGoogleスプレッドシートを準備します。ここでは先程ダウンロードしたJSONファイルを使用するため、ご準備ください。
まず、ご自身のGoogleアカウントにアクセスしたあとに、スプレッドシートを選択します。
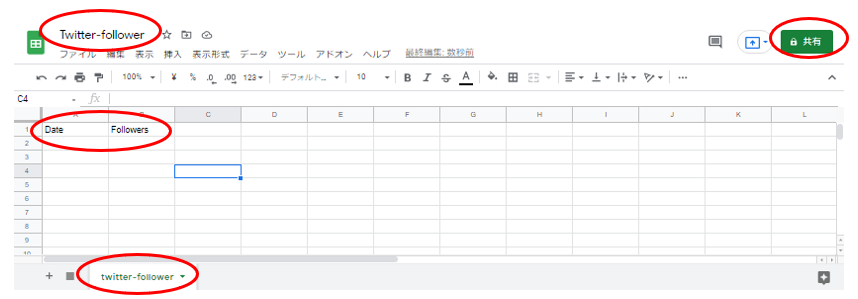
スプレッドシートを作成したら、ファイル名とシート名と記載しましょう。本記事では、どちらも”Twitter-follower”としました。また、わかりやすいように図15のようにA1とB1にカラム名(Date、Followers)を記載しておきましょう。
このスプレッドシートに先程作成したAPIからアクセスできるように、”編集者権限”を付与しておきます。画面右上の”共有”を押してください。
そうすると、”ユーザーやグループと共有”の項目が出てます。
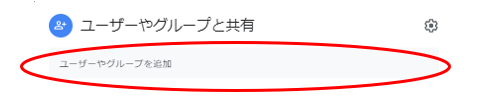
ここで、先程ダウンロードしたJSONファイルを開き、”client_email”の値をコピーして、図16のBOXに貼り付けます。(値の””(ダブルコーテション)は不要です。)

これでスプレッドシートにアクセスする準備が整いました。ここからPythonコードを記載していきます。
4. テスト環境コード
4-1. GCP APIの認証コードを書く
ここからはPythonコードを作成していきます。テスト環境のフォルダー構成は以下です。
.
|─main.py
|─gcp_secret.json
└─secret_twittwer.json前回記事でTwitter API使用によるフォロワー数取得コードは説明済みなので、そこまでのコードは以下で実装されます。
今回の記事は、テスト環境と本番環境を同じmain.pyに記載していくので、環境を選択できる”MODE”という変数を用意します。本番環境用のコードは後ほど記載していきますので、現状は”pass”コードのみ記載しています。
import csv
import tweepy
import json
import pandas as pd
MODE = "Test"
def twitter_authorization():
if MODE == "Test":
with open('./secret_twitter.json') as f:
twitter_keys = json.load(f)
consumer_key = twitter_keys["consumer_key"]
consumer_secret = twitter_keys["consumer_secret"]
access_token = twitter_keys["access_token"]
access_token_secret = twitter_keys["access_token_secret"]
if MODE == "Prod":
pass
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
return tweepy.API(auth)
def get_n_followers(api):
n_followers = api.me().followers_count
return n_followers
Google APIの認証を行います。pip等でgoogle、gspread、gspread_dataframeのLibraryをインストール後、以下のコードを記載してみてください。
from google.oauth2.service_account import Credentials
import gspread
def get_gspread():
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
if MODE == "Test":
credentials = Credentials.from_service_account_file(
'gcp_secret.json',
scopes=scopes
)
SP_SHEET_KEY = '{Your Spread Sheet Key}'
SP_SHEET = '{Your Spread Sheet}'
if MODE == "Prod":
pass
gc = gspread.authorize(credentials)
sh = gc.open_by_key(SP_SHEET_KEY)
ws = sh.worksheet(SP_SHEET)
return wsScopesは認証権限を指定できます。詳しくはこちらをご覧ください。
“Credentials.from_service_account_file”でgcp_secret.josn”を読み込んで、scopesの権限で認証を行います。詳しくはこちらから。
次にスプレッドシートの情報を入力します。SP_SHEET_KEYは、スプレッドシートのURLをからわかります。以下の図の赤線箇所をコピーして、文字列型で指定してください。SP_SHEETは、シートのタグ名なので、本記事では”twitter-follower”とします。
SP_SHEET_KEYなどをコードに記載したくない方は、JSONファイルなどにキーと値を記載して、読み込んでいただいてもOKです。

あとは、スプレッドシートを読み込んでインスタンス化します。これでGCP APIの認証コードは完成です。
4-2. スプレッドシート書き込みコード
スプレッドシートへTwitter情報を書き込みコードを記載していきます。以下のコードを記載ください。
from datetime import datetime
from gspread_dataframe import set_with_dataframe
def gcp_writer(n_followers):
date_today = datetime.today().timetuple()
date = f'{date_today.tm_year}-{date_today.tm_mon}-{date_today.tm_mday}'
data_dcit = {'Date': f'{date}', 'Followers': f'{n_followers}'}
ws = get_gspread()
df = pd.DataFrame(ws.get_all_values()[1:], columns=ws.get_all_values()[0])
df = df.append(data_dcit, ignore_index=True)
set_with_dataframe(ws, df, row=1, col=1)コードの流れは以下です。
- 登録日付(date)は関数内の最初の2行で取得します。
- “date”とTwitterAPIで取得した”n_followers”を辞書型とします。
- 先程スプレッドシート取得インスタンスを読み込んで、スプレッドシート内のデータを取得し、pandasのデータフレーム型にします。
- 辞書データをデータフレームに追加します。
- gspread_dataframeライブラリのset_with_dataframe関数を用いて、④のデータフレームをスプレッドシートに上書きします。
これでTwitterデータをスプレッドシートに保存できます。
4-3. テスト環境で実行する
テスト環境で実行し、データが保存されるか確認します。main関数を以下のようにします。
def main():
api = twitter_authorization()
n_followers = get_n_followers(api)
gcp_writer(n_followers)
if __name__ == "__main__":
main()ターミナル等でmain.pyを実行します。
$ python3 mian.pyスプレッドシートを確認して、データが保存されていれば成功です!
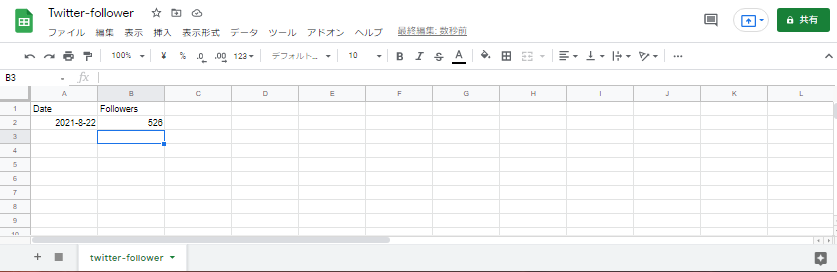
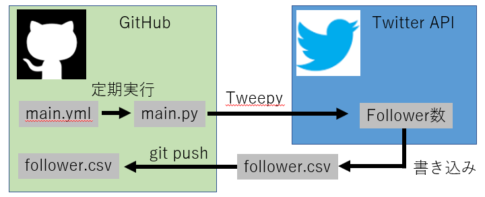
これで自動化に向けたpython処理コードは完成です。あとは自動化するためのGitHub上の設定と本番環境コードを行います。
5. GitHub設定
5-1. GitHub上での準備 (リポジトリ作成)
GitHubにアクセスします。アカウントがない方は新たに登録してみてください。登録の参考記事は以下や公式サイトをご確認ください。ここで登録した名前やアドレスは後ほど使用するため、控えていただけると後で楽です。
今回は、GitHubアカウントの作成方法についてステップバイステップ(画面付き)でご紹介していきます。
GitHubアカウントの作成方法 (2021年版)
登録が完了したら、新しくリポジトリを作成します。そうすると図20のような画面に移るので、リポジトリの名前と公開範囲を’Private’にします。リポジトリ名は’twitter-follower-prod’としています。
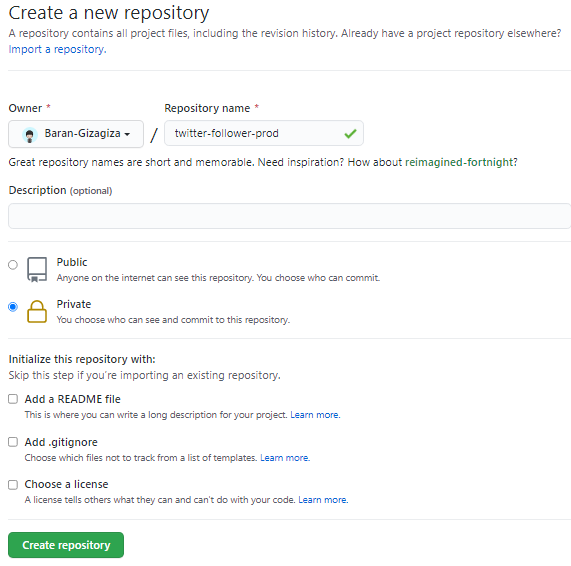
記入したら、’Create repository’をクリックして作成完了です。
次にローカルPCとGitHubを紐付けます。図4のような画面が表示されたら、’HTTPS’を選択し、URLをコピーします。

コピーしたら、ターミナルで先程まで作業していたフォルダーに移ります。移動しましたら、コピーしたURLで以下のコマンドを実行し、GitHubとローカルPCを接続します。
$ git clone https://github.com/{Your Name}/twitter-follower-prod.gitそうすると、以下のように’twitter-follower-prod’のフォルダーが新たに作成されます。今後はこの’twitter-follower-prod’フォルダー内で作業を行います。
.
|─main.py
|─gcp_secret.json
|─secret_twittwer.json
└─twitter-follower-prod
└─.gitなお、‘HTTPS’でのGitHubへのアクセスは2021年8月13日で終了するため、他の接続方法が必要です。SSHによる認証設定方法は、以下の記事に記載していますのでご参考ください。

5-2. GitHub上で環境変数を設定する
次に環境変数を設定します。テスト環境では、JSONファイルでTwitterAPIやGoogleAPIにアクセスするキーを読み込みましたが、GitHub上に情報データをアップロードするのは、セキュリティ上よくありません。
そこでGitHubの’Secrets’機能を利用して、GitHubにTwitterAPIやGoogleAPIにアクセスするキーを登録しておきます。これで、JSONファイルをアップロードすることなく、アクセスキーを利用することが可能です。
まずは、GitHubのリポジトリ内にある’Settings‘を選択します。

そうしたら、’Secrets’ => ‘New repository secret’の順で選択します。
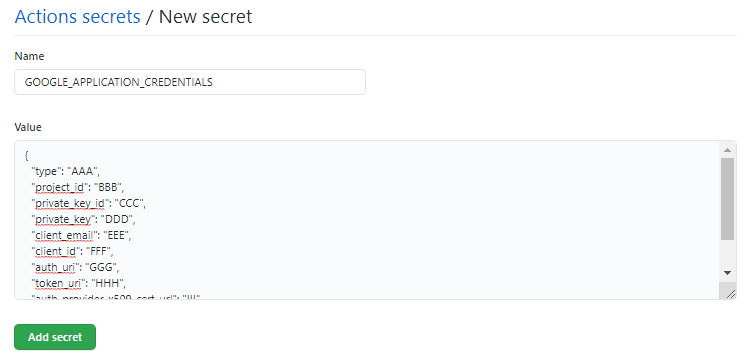
以下の画面で、TwitterAPIやGoogleAPIにアクセスするために必要なキーとその値を入力します。とくにGoogle認証は、図24のように辞書型のまま、値を貼り付けてください。
なお、文字列を表す’ “(ダブルクオテーションなど) ‘は入力する必要はありません。
以下のように設定できていたらOKです。
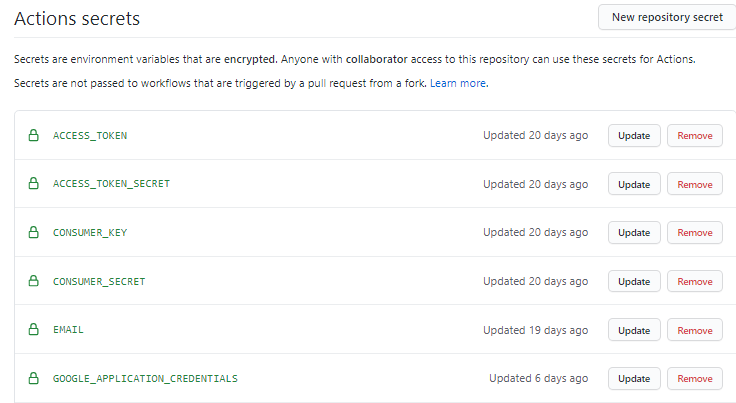
また、定期実行を実施するため、GitHub登録時に指定した名前とアドレスを環境変数にしておきます。
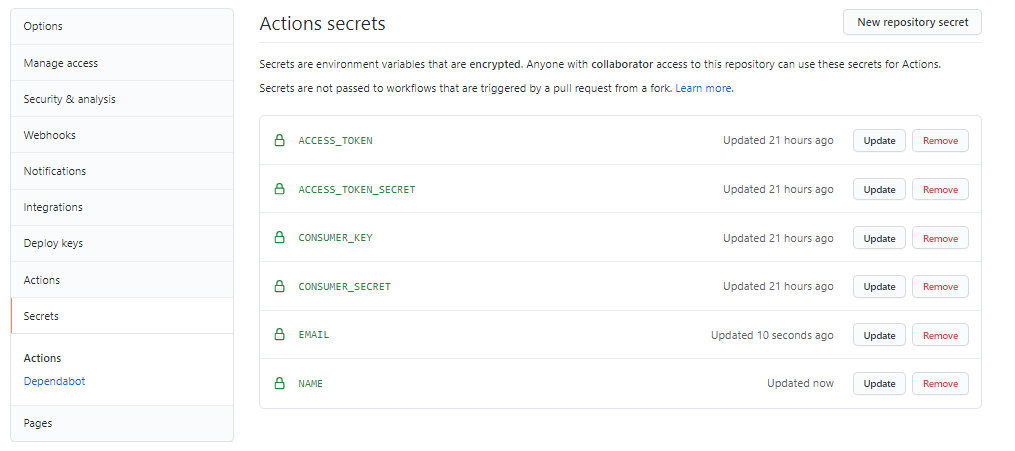
これでGitHub上での環境変数の設定は完了です。
6. 本番環境と自動化
本番環境は以下のフォルダー構成になります。
.
|─main.py
|─gcp_secret.json
|─secret_twittwer.json
└─twitter-follower-prod
|─.git
|─.github
| └─workflows
| └─main.yml
|─.gitignore
|─main.py
└─requirements.txt6-1. 本番環境用コードの記載
主にJSONファイルによる認証を環境変数に変更します。本番環境では、機密情報であるJSONファイルをアップロードいないほうが良いため、環境変数を設定し、その値を読み込むようにコードを記載します。
環境変数は”os.environ“で取得できます。先程GitHub上に設定した環境変数使用するため、ここでは環境変数を読み込むコードを記載していきます。
import os
import json
MODE = "Prod"
def twitter_authorization():
if MODE == "Test":
""" 省略 """
if MODE == "Prod":
consumer_key = os.environ.get("CONSUMER_KEY")
consumer_secret = os.environ.get("CONSUMER_SECRET")
access_token = os.environ.get("ACCESS_TOKEN")
access_token_secret = os.environ.get("ACCESS_TOKEN_SECRET")
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
return tweepy.API(auth)
def get_gspread():
if MODE == "Test":
""" 省略 """
if MODE == "Prod":
SECRETS = json.loads(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
credentials = Credentials.from_service_account_info(
SECRETS,
scopes=scopes
)
SP_SHEET_KEY = os.environ.get("SP_SHEET_KEY")
SP_SHEET = os.environ.get("SP_SHEET")
gc = gspread.authorize(credentials)
sh = gc.open_by_key(SP_SHEET_KEY)
ws = sh.worksheet(SP_SHEET)
return wsTwitterAPIの環境変数設定は前回記事をご確認ください。
Google認証は辞書型で定義されているため、文字列を辞書型で読み込む、”json.loadsと”Credentials.from_service_account_info”を用いて認証を実施しています。
6-2. 本番環境の使用Libraryを記載
“requirements.txt”に標準ライブラリ以外の使用するLibraryを記載します。
pandas
tweepy
gspread
google
gspread_dataframe6-3. gitignore指定
念の為、JSONファイルはアップロードしないように、”.gitignore”ファイルを作成し、以下のように記載します。
*.json6-4. 定期実行スクリプト(main.yml)の準備
最後に定期実行を行うために、’.github/workflows/main.yml’を作成します。
GitHub上で定期実行するためには、’main.py’のファイルパスを’.github/workflows/main.yml’とする必要がある点にご注意ください。詳しくはこちらから。
name: twitter-follower-prod
on:
push:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v1
with:
python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
- name: Run main script
env:
CONSUMER_KEY: ${{ secrets.CONSUMER_KEY }}
CONSUMER_SECRET: ${{ secrets.CONSUMER_SECRET }}
ACCESS_TOKEN: ${{ secrets.ACCESS_TOKEN }}
ACCESS_TOKEN_SECRET: ${{ secrets.ACCESS_TOKEN_SECRET }}
GOOGLE_APPLICATION_CREDENTIALS: ${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}
run: |
python main.py
- name: CSV commit
run: |
git config --global user.email ${{ secrets.EMAIL }}
git config --global user.name ${{ secrets.NAME }}
git add .
git commit -m "Update GCP-Spread Sheet"
git push origin mainこれですべてのファイルが用意できたので、GitHubへpush時にコードがしっかり実行されるか確認します。
7. GitHubにPushする
7-1. Push時にスクリプトを実行する
コードが完成したら、コードファイルをGitHubへpushします。ターミナルで’twitter-follower-prod’のフォルダーに移動し、以下のコマンドを実行します。
$ git add .
$ git commit -m "1st Commit"
$ git push origin mainそうすると、Google Spread Sheetが更新されるはずです。
ここまでできていれば、コードは問題なしです。あとは定期実行させるために、’main.yml’をちょっと変更します。
あと一息です!
7-2. 定期実行用にmain.ymlを変更し、再度GitHubにPushする
一度、GitHub上のファイルをpullしておきます。ターミナルで’twitter-follower-prod’のフォルダーに移動し、以下のコマンドを実行します。
$ git pull origin mainでは、’main.yml’に変更を加えます。といってもpushを削除して、scheduleを加えるだけです。
name: twitter-follower-prod
on:
schedule:
- cron: '0 24 * * *'
# 以下同様こちらにもありますように、scheduleはUTC時間のみで記載できるため、日本だと9時間の時差を考慮して設定する必要があります。
上記であれば、UTC 24時なので、日本時間で毎朝9時に定期実行することになります。
あとは、先程と同様にGitHubにファイルをpushします。これで次の日の朝9時から、毎日twitterフォロワー数をGoogle スプレッドシートに記録する仕組みができました。
$ git add .
$ git commit -m "Update main.yml file"
$ git push origin mainお疲れさまでした!
8. まとめ
長っかたですが、本記事でDBの設定なく取得したデータ保存する仕組みを定期実行することができました。
一度作成すれば、あとは取得するデータ構造の変更などは容易だと思います。
また、Google Spread Sheetにデータが保存されるので、Googleアカウントにアクセスできる時はいつでもデータを閲覧することが可能です。
その他のAPIを組み合わたり、スクレイピングを活用して多くのデータを自動で収集することできそうですね。
ぜひ、本記事を例に色々な自動化に挑戦してみてください!
それでは、よいPythonライフを!
以下の記事も書いています。よかったらご覧ください。

Twitterもやってまーす。



Pythonバージョンが3.8以上あれば、本記事のコードは動くと思います。