

今回は、kaggleのタイタニックデータを用いて、機械学習のWebアプリをDockerおよびPython-Streamlitで実装してみたいと思います。
今回はkaggleデータを取得して、欠損値の処理前後のデータ数を表示していきます。
▼ Contents
1. Streamlitとは
詳しくは、Streamlitで確認してみてください。
大まかな内容は
- PythonコードのみでWebアプリを作成できる
- HTML, CSS不要
- 公式ドキュメントが充実しているので実装しやすい
- Pythonコードで閉じるので、初心者でもわかりやすい
手頃にWebアプリを作成して、シェアしたいときなどには重宝しそうです。
それでは、実装していきましょう。
2. 前回記事
以下の本記事内容は、Docker環境で構築したAnacondaをベースに作成し、kaggleのタイタニックデータを使用しています。構築方法やデータ取得方法が不明な方は以下の記事をご参考ください。

3. 基本コードを書く
最初は、”Streamlit”は気にせずに通常通りデータ処理のコードを記載していきます。
欠損値を処理する関数”missing_value”を”data_get.py”に作成していきます。
まずは、処理前(Before)の結果として、alldataの欠損値をpandasのデータフレームで確認します。(alldata.isnull().sum())
次にalldataに欠損値の処理を施します。
ここは皆様の好きなように処理指定いただいてOKですが、今回は
- カラム”Embarked”には最頻値を代入する
- カラム”Fare”には中央値を代入する
としました。
そしてalldata処理後(After)のpandasデータフレームを表示します。
戻り値は欠損値処理後のalldataとします。
""" data_get.py """
import pandas as pd
import streamlit as st
class Data_Get():
def read_data(self):
""" 記事その1を参照ください。 """
def missing_value(self, alldata):
print("Before")
print(alldata.isnull().sum())
""" Embarkedには最頻値を代入 """
alldata['Embarked'].fillna(alldata['Embarked'].mode()[0], inplace=True)
""" Fareには中央値を代入 """
alldata['Fare'].fillna(alldata['Fare'].median(), inplace=True)
print("After")
print(alldata.isnull().sum())
return alldata 次に”main_streamlit.py”を作成します。こちらは簡単で、先程作成したdata_get.pyからData_Getインスタンスを読み込み、missing_value関数を使用して、alldataに欠損値処理を施します。
以上です。
""" main.py """
import pandas as pd
import streamlit as st
import data_get as dg
print('Titanic - Machine Learning from Disaster')
print('(1) Data Structure')
dg_Inst = dg.Data_Get()
alldata, test_raw = dg_Inst.read_data()
st.subheader('(2) Missing Value')
alldata = dg_Inst.missing_value(alldata)それでは、前回と同じようにターミナルにてstreamlitを起動しましょう。
$ streamlit run main_streamlit.pyまだ、Webアプリに変化はありませんが、エラーがなければ処理自体はうまく行っていると思います。
4. Streamlitを実装する
ここからStreamlitを実装して、Webアプリを作成していきます!
“main.py”を以下のように変更します。
""" main_streamlit.py """
import pandas as pd
import streamlit as st
import data_get as dg
st.title('Titanic - Machine Learning from Disaster')
st.subheader('(1) Data Structure')
dg_Inst = dg.Data_Get()
alldata, test_raw = dg_Inst.read_data()
st.subheader('(2) Missing Value')
st.write('Please coding your method for missing value')
alldata = dg_Inst.missing_value(alldata)次に”data_get.py”を変更していきます。以下のように変更してみてください。
""" data_get.py """
import pandas as pd
import streamlit as st
class Data_Get():
def read_data(self):
""" 記事その1をご参照ください。 """
return alldata, test_raw
def missing_value(self, alldata):
with st.beta_container():
col1, col2 = st.beta_columns([1, 1])
with col1:
st.subheader("Before")
st.write(alldata.isnull().sum())
alldata['Embarked'].fillna(alldata['Embarked'].mode()[0], inplace=True)
alldata['Fare'].fillna(alldata['Fare'].median(), inplace=True)
with col2:
st.subheader("After")
st.write(alldata.isnull().sum())
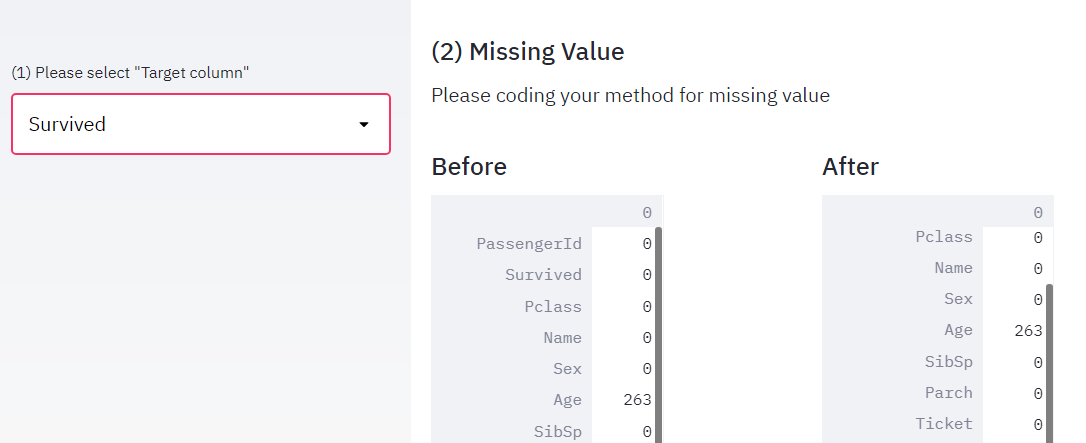
return alldataコードを変更して”localhost:8501″を更新すると、以下のようにWebアプリが変更されます。
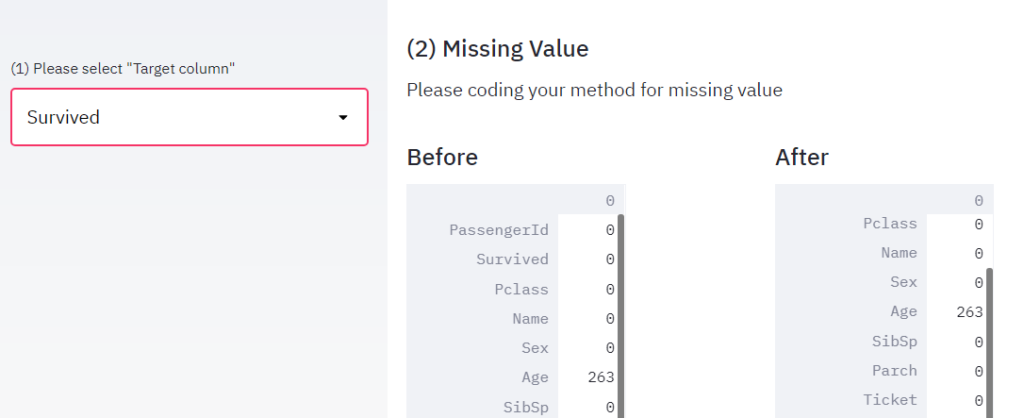
コードを確認していきます。
以下のコードでは、まず大枠(container)を作成し、その中のコンテンツ(col1, col2)を作成します。
st.beta_columnsの引数は、container内のcol1, col2の占める割合を指定できます。
例えば、[1, 1]と指定すると図2のように1:1のように表示されます。[2, 1]とすれば図3のように2:1のように表示されます。
なお、3つ以上の場合でも適用可能です。(表示は小さくなるので2つあたりが良いかと個人的には思います。大画面があれば別ですが。)
with st.beta_container():
col1, col2 = st.beta_columns([1, 1])
with col1:
st.subheader("Before")
st.write(alldata.isnull().sum())
alldata['Embarked'].fillna(alldata['Embarked'].mode()[0], inplace=True)
alldata['Fare'].fillna(alldata['Fare'].median(), inplace=True)
with col2:
st.subheader("After")
st.write(alldata.isnull().sum())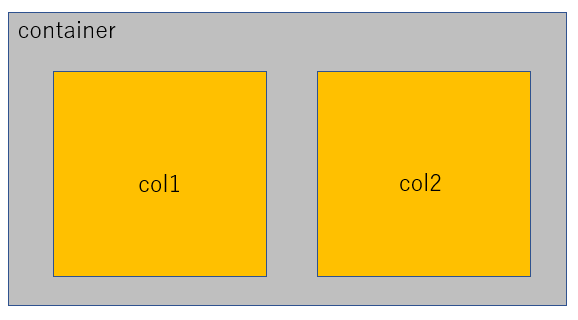
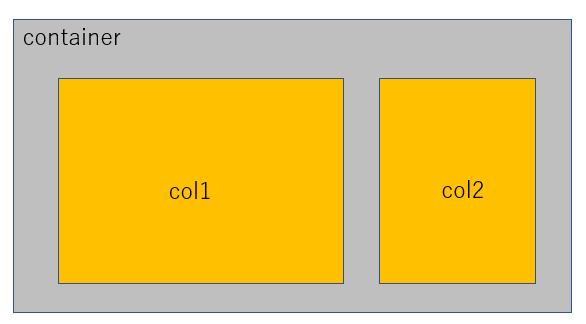
最後に欠損値処理の具合を表で確認しておきましょう。
確かに”Fare”と”Embarked”の欠損値が0になり、何らかの処理が行われているようです。

5. 本記事の完成形とまとめ
本記事内の内容での完成形のコードを以下に示します。
""" main_streamlit.py """
import pandas as pd
import streamlit as st
import data_get as dg
st.title('Titanic - Machine Learning from Disaster')
st.subheader('(1) Data Sturucture')
dg_Inst = dg.Data_Get()
alldata, test_raw = dg_Inst.read_data()
st.subheader('(2) Missing Value')
st.write('Please coding your method for missing value')
alldata = dg_Inst.missing_value(alldata)""" data_get.py """
import pandas as pd
import streamlit as st
class Data_Get():
def read_data(self):
""" 記事その1をご参照ください。 """
return alldata, test_raw
def missing_value(self, alldata):
with st.beta_container():
col1, col2 = st.beta_columns([1, 1])
with col1:
st.subheader("Before")
st.write(alldata.isnull().sum())
alldata['Embarked'].fillna(alldata['Embarked'].mode()[0], inplace=True)
alldata['Fare'].fillna(alldata['Fare'].median(), inplace=True)
with col2:
st.subheader("After")
st.write(alldata.isnull().sum())
return alldata以上のように、pythonコードのみでWebアプリ動作が可能であるので、動作させながら結果を見たい場合などに重宝しそうです。
今回は欠損値の処理前後の欠損値数を表で確認できるWebアプリを作成してみました。
次回は、データ前処理内容をグラフで確認できるWebアプリをStreamlitで実装してみたいと思います。
それではよいpython-streamlit ライフを!以下、関連記事となります。合わせてお読みいただけるお幸いです。





コメントを残す