

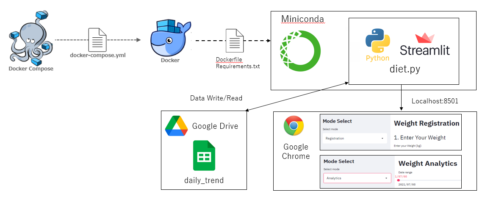
今回は、kaggleのタイタニックデータを用いて、機械学習のWebアプリをDockerおよびPython-Streamlitで実装してみたいと思います。
今回は機械学習前のデータ前処理具合を可視化していきたいと思います。
▼ Contents
1. Streamlitとは
詳しくは、Streamlitで確認してみてください。
大まかな内容は
- PythonコードのみでWebアプリを作成できる
- HTML, CSS不要
- 公式ドキュメントが充実しているので実装しやすい
- Pythonコードで閉じるので、初心者でもわかりやすい
手頃にWebアプリを作成して、シェアしたいときなどには重宝しそうです。
それでは、実装していきましょう。
2. 前回記事
以下の本記事内容は、Docker環境で構築したAnacondaをベースに作成しています。予めご了承ください。
使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
ファイルフォルダー構成は以下です。
.
|-- docker-compose.yml
`-- work
|-- Dockerfile
|-- requirements.txt
`-- kaggle
`-- taitanic
|-- data
| |-- test.csv
| `-- train.csv
`-- streamlit
|-- main_streamlit.py
|-- data_get.py
`-- preprocessing.py以下の本記事内容は、Docker環境で構築したAnacondaをベースに作成し、kaggleのタイタニックデータを使用しています。構築方法やデータ取得方法が不明な方は以下の記事をご参考ください。

3. 基本コード(前処理)を書く
最初は、”Streamlit”は気にせずに通常通りデータ処理のコードを記載していきます。個人的には、一旦基本コードを完成させたほうがStreamlitも記載するのが楽かなと思います。
今回処理するデータ項目は、「Fare」と「Age」、そして「Cabin」を処理していきます。
まずは各データの前処理コードを記載していきます。(ちょっと長いですが。。。)
「Fare」と「Age」、「Cabin」の処理内容の概要は以下です。
「Fare」: “bins”で分割数を決定し、通常スケールとLogスケールのヒストグラムを表示します。
""" preprocessing.py """
import pandas as pd
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def fare_processing(self,alldata_sum):
print("(3)-1. Fare")
bins = 30
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Common scale')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Fare'],kde=False,rug=False,bins=bins,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Fare'],kde=False,rug=False,bins=bins,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
axes[1].set_title('Log scale')
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==1]['Fare']),kde=False,rug=False,bins=bins,label='Survived', ax=axes[1])
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==0]['Fare']),kde=False,rug=False,bins=bins,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
plt.show()
alldata_sum.loc[:, 'Fare_bin'] = pd.qcut(alldata_sum['Fare'], bins)
return alldata_sum
「Age」: 欠損値の処理に対して、”除外”、”平均値で補完”、”中央値で補完”を選択し、その結果をグラフで表示します。
""" preprocessing.py """
import pandas as pd
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def age_processing(self, alldata_sum):
print("(3)-2. Age")
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Before')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
solution = "Exclude"
if solution == "Exclude": """ Ageの欠損を除外 """
alldata_sum = alldata_sum[~((alldata_sum['train_or_test'] == 0) & (alldata_sum['Age'].isnull()))]
elif solution == "Mean": """ Ageの欠損を平均値で補完 """
age_avg = alldata_sum['Age'].mean()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_avg)
else solution == "Median": """ Ageの欠損を中央値で補完 """
age_median = alldata_sum['Age'].median()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_median)
axes[1].set_title('After')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[1])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
plt.show()
return alldata_sum「Cabin」: Cabinの頭文字別の生存率とレコード数から、少数派の頭文字を一括にします。
""" preprocessing.py """
import pandas as pd
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def cabin_processing(self, alldata_sum):
print("(3)-3. Cabin")
alldata_sum['Cabin_init'] = alldata_sum['Cabin'].apply(lambda x: str(x)[0])
print("Mean vs count")
""" Cabinの頭文字別の生存率とレコード数 """
print(alldata_sum[alldata_sum['train_or_test'] == 0]['Survived'].groupby(alldata_sum['Cabin_init']).agg(['mean','count']))
print("Before")
""" Cabinの頭文字別の生存率とレコード数 """
print(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
""" 少数派のCabin_initを統合 """
alldata_sum['Cabin_init'].replace(['G','T'], 'Rare',inplace=True)
print("After")
""" Cabinの頭文字別の生存率とレコード数 """
print(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
return alldata_sum前処理のコードが書き終わったら、Streamlitを実装していきましょう。
4. Streamlit実装
まず、”main_streamlit.py”を以下のように記載します。
""" main_streamlit.py """
import pandas as pd
import streamlit as st
import data_get as dg
import preprocessing as pr
st.title('Titanic - Machine Learning from Disaster')
st.subheader('(1) Data Sturucture')
""" 記事その1をご参照ください。 """
dg_Inst = dg.Data_Get()
alldata, test_raw = dg_Inst.read_data()
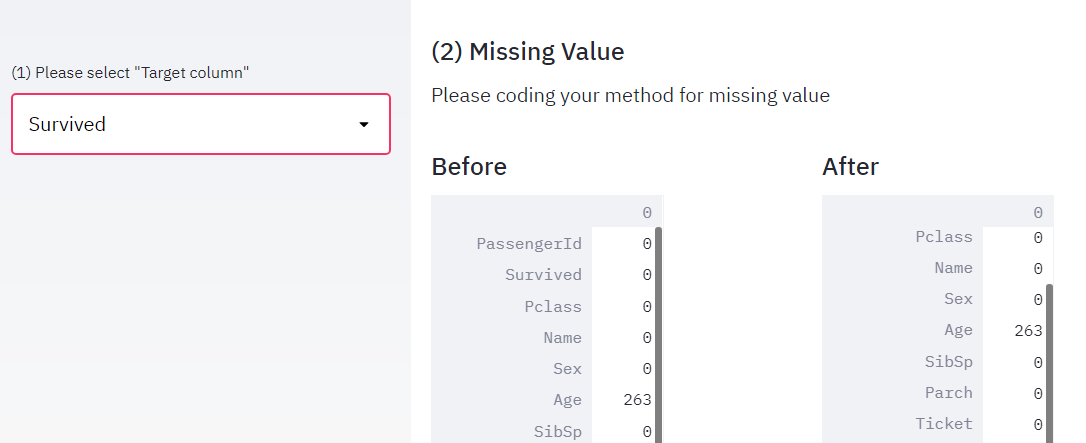
st.subheader('(2) Missing Value')
""" 記事その2をご参照ください。 """
st.write('Please coding your method for missing value')
alldata = dg_Inst.missing_value(alldata)
st.subheader('(3) Preprocessing')
st.write('Please coding your method for preprocessing')
alldata_sum = alldata.copy()
pp_Inst = pr.Preprocessing()
alldata_sum = pp_Inst.fare_processing(alldata_sum)
alldata_sum = pp_Inst.age_processing(alldata_sum)
alldata_sum = pp_Inst.cabin_processing(alldata_sum) main_streamlit.pyが書けましたら、以下のコマンドをターミナルで実行してみましょう。
それでは、前回と同じようにターミナルにてstreamlitを起動しましょう。
$ streamlit run main_streamlit.pyそうすると、通常通りであれば”localhost:8501″に以下のような画面が表示されると思います。

動作に問題なければ、”preprocessing.py”のコードにStreamlitを実装していきます。
それぞれの前処理に以下を実装してみます。
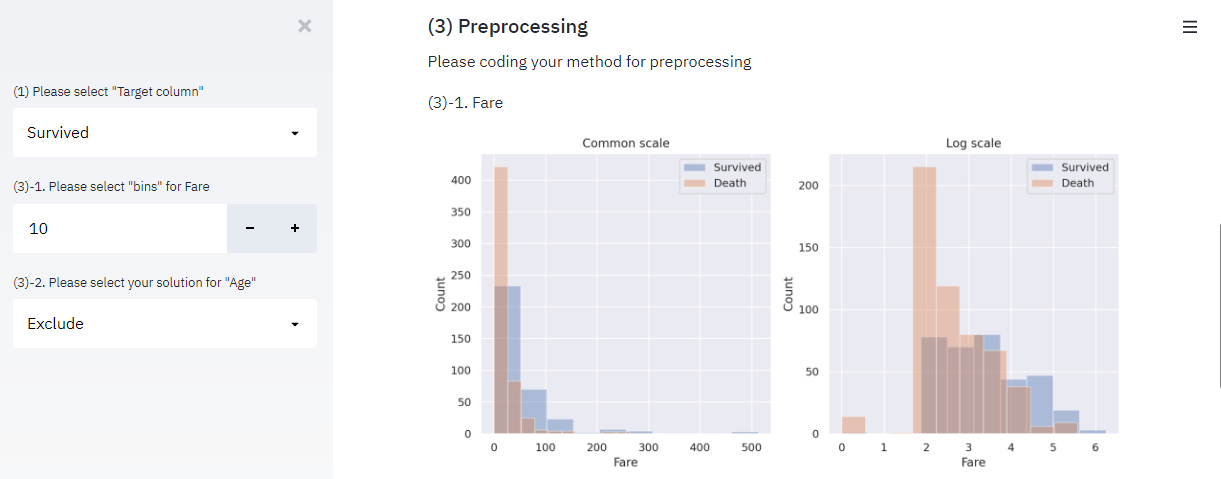
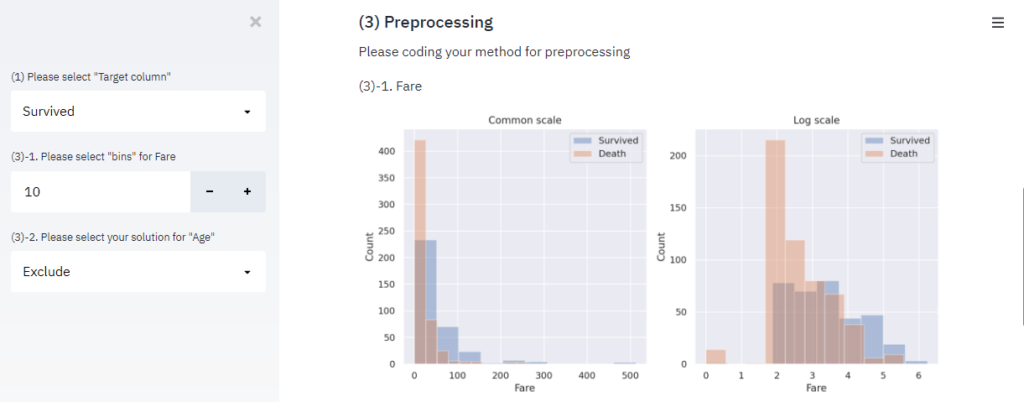
「Fare」: “bins”で分割数を決定する数値入力欄を用意し、binsに応じた通常スケールとLogスケールの「Fare」ヒストグラムを表示します。
""" preprocessing.py """
import pandas as pd
import numpy as np
import streamlit as st
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def fare_processing(self,alldata_sum):
st.write("(3)-1. Fare")
bins = st.sidebar.number_input(
'(3)-1. Please select "bins" for Fare',
min_value=2,
max_value=100,
value=10
)
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Common scale')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Fare'],kde=False,rug=False,bins=bins,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Fare'],kde=False,rug=False,bins=bins,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
axes[1].set_title('Log scale')
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==1]['Fare']),kde=False,rug=False,bins=bins,label='Survived', ax=axes[1])
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==0]['Fare']),kde=False,rug=False,bins=bins,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
st.pyplot(fig)
alldata_sum.loc[:, 'Fare_bin'] = pd.qcut(alldata_sum['Fare'], bins)
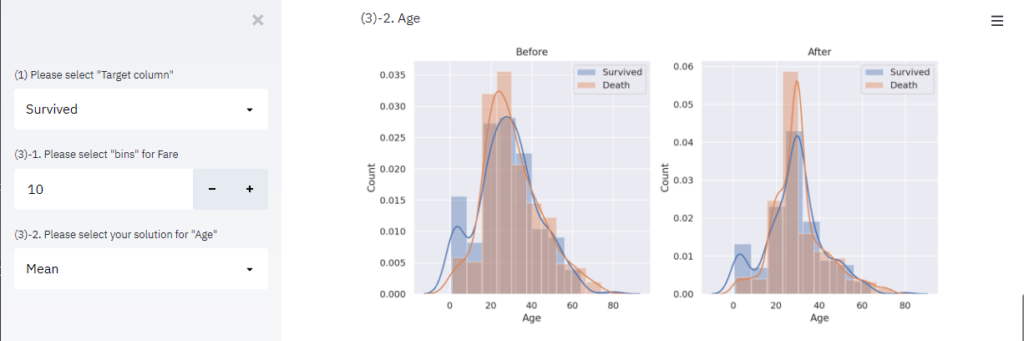
return alldata_sum「Age」: 欠損値の処理に対して、”除外(exclude)”、”平均値で補完(Mean)”、”中央値で補完(Median)”を選択する選択BOXを用意し、選択した項目の処理を実行します。
""" preprocessing.py """
import pandas as pd
import numpy as np
import streamlit as st
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def age_processing(self, alldata_sum):
st.write("(3)-2. Age")
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Before')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
solution = st.sidebar.selectbox(
'(3)-2. Please select your solution for "Age"',
["Exclude", "Mean", "Median"]
)
if solution == "Exclude":
alldata_sum = alldata_sum[~((alldata_sum['train_or_test'] == 0) & (alldata_sum['Age'].isnull()))]
elif solution == "Mean":
age_avg = alldata_sum['Age'].mean()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_avg)
else solution == "Median":
age_median = alldata_sum['Age'].median()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_median)
axes[1].set_title('After')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[1])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
st.pyplot(fig)
return alldata_sum「Cabin」: Cabinの頭文字別の生存率とレコード数から、少数派の頭文字を一括処理する前後の生存数(0: Death, 1:Survived)を表示します 。
""" preprocessing.py """
import pandas as pd
import numpy as np
import streamlit as st
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def cabin_processing(self, alldata_sum):
st.write("(3)-3. Cabin")
alldata_sum['Cabin_init'] = alldata_sum['Cabin'].apply(lambda x: str(x)[0])
with st.beta_container():
col1, col2, col3 = st.beta_columns([1, 1, 1])
with col1:
st.write("Mean vs count")
st.write(alldata_sum[alldata_sum['train_or_test'] == 0]['Survived'].groupby(alldata_sum['Cabin_init']).agg(['mean','count']))
with col2:
st.write("Before")
st.write(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
alldata_sum['Cabin_init'].replace(['G','T'], 'Rare',inplace=True)
with col3:
st.write("After")
st.write(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
return alldata_sum上記コードを実装後に、再度Web上で更新すれば、以下の図のような結果が表示されているはずです。
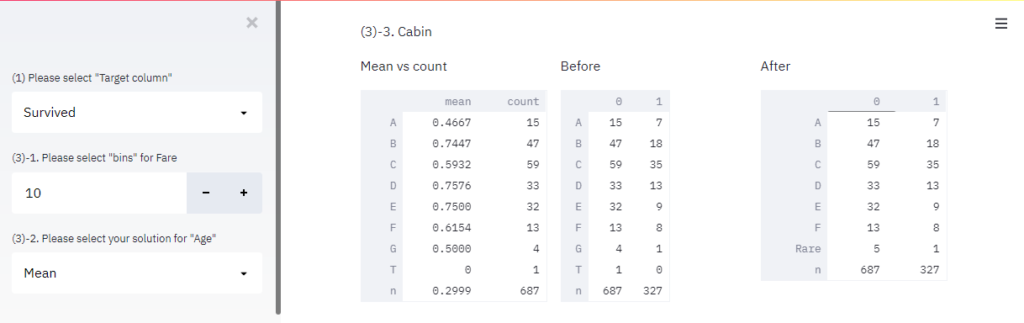
処理内容が簡単に比較できるので、便利ですね!
5. 完成コードとまとめ
本記事内の内容での完成形のコードを以下に示します。
""" main_streamlit.py """
import pandas as pd
import streamlit as st
import data_get as dg
import preprocessing as pr
st.title('Titanic - Machine Learning from Disaster')
st.subheader('(1) Data Sturucture')
""" 記事その1をご参照ください。 """
dg_Inst = dg.Data_Get()
alldata, test_raw = dg_Inst.read_data()
st.subheader('(2) Missing Value')
""" 記事その2をご参照ください。 """
st.write('Please coding your method for missing value')
alldata = dg_Inst.missing_value(alldata)
st.subheader('(3) Preprocessing')
st.write('Please coding your method for preprocessing')
alldata_sum = alldata.copy()
pp_Inst = pr.Preprocessing()
alldata_sum = pp_Inst.fare_processing(alldata_sum)
alldata_sum = pp_Inst.age_processing(alldata_sum)
alldata_sum = pp_Inst.cabin_processing(alldata_sum)""" preprocessing.py """
import pandas as pd
import numpy as np
import streamlit as st
import seaborn as sns; sns.set(font='DejaVu Sans')
import matplotlib.pyplot as plt
class Preprocessing():
def fare_processing(self,alldata_sum):
st.write("(3)-1. Fare")
bins = st.sidebar.number_input(
'(3)-1. Please select "bins" for Fare',
min_value=2,
max_value=100,
value=10
)
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Common scale')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Fare'],kde=False,rug=False,bins=bins,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Fare'],kde=False,rug=False,bins=bins,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
axes[1].set_title('Log scale')
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==1]['Fare']),kde=False,rug=False,bins=bins,label='Survived', ax=axes[1])
sns.distplot(np.log1p(alldata_sum[alldata_sum['Survived']==0]['Fare']),kde=False,rug=False,bins=bins,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
st.pyplot(fig)
alldata_sum.loc[:, 'Fare_bin'] = pd.qcut(alldata_sum['Fare'], bins)
return alldata_sum
def age_processing(self, alldata_sum):
st.write("(3)-2. Age")
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].set_title('Before')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[0])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[0])
axes[0].set_ylabel('Count')
solution = st.sidebar.selectbox(
'(3)-2. Please select your solution for "Age"',
["Exclude", "Mean", "Median"]
)
if solution == "Exclude":
alldata_sum = alldata_sum[~((alldata_sum['train_or_test'] == 0) & (alldata_sum['Age'].isnull()))]
elif solution == "Mean":
age_avg = alldata_sum['Age'].mean()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_avg)
else solution == "Median":
age_median = alldata_sum['Age'].median()
alldata_sum['Age'] = alldata_sum['Age'].fillna(age_median)
axes[1].set_title('After')
sns.distplot(alldata_sum[alldata_sum['Survived']==1]['Age'],kde=True,rug=False,bins=10,label='Survived', ax=axes[1])
sns.distplot(alldata_sum[alldata_sum['Survived']==0]['Age'],kde=True,rug=False,bins=10,label='Death', ax=axes[1])
axes[1].set_ylabel('Count')
axes[0].legend()
axes[1].legend()
fig.tight_layout()
st.pyplot(fig)
return alldata_sum
def cabin_processing(self, alldata_sum):
st.write("(3)-3. Cabin")
alldata_sum['Cabin_init'] = alldata_sum['Cabin'].apply(lambda x: str(x)[0])
with st.beta_container():
col1, col2, col3 = st.beta_columns([1, 1, 1])
with col1:
st.write("Mean vs count")
st.write(alldata_sum[alldata_sum['train_or_test'] == 0]['Survived'].groupby(alldata_sum['Cabin_init']).agg(['mean','count']))
with col2:
st.write("Before")
st.write(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
alldata_sum['Cabin_init'].replace(['G','T'], 'Rare',inplace=True)
with col3:
st.write("After")
st.write(pd.crosstab(alldata_sum['Cabin_init'],alldata_sum['train_or_test']))
return alldata_sum今回はデータ目処理前後の結果を簡単なパラメータ調整で表示させるWebアプリを作成してみました。
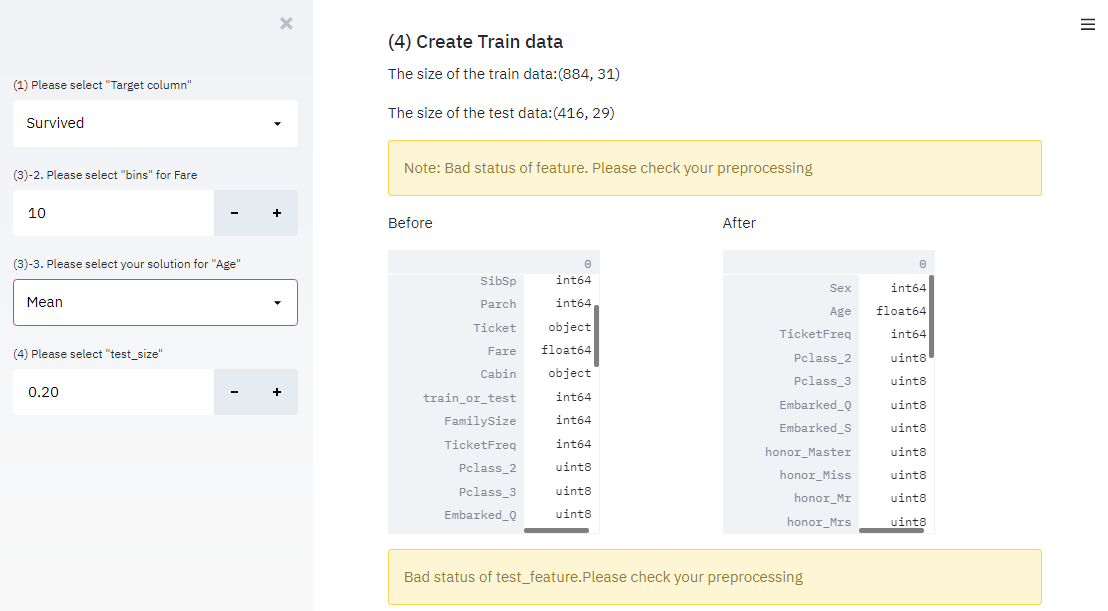
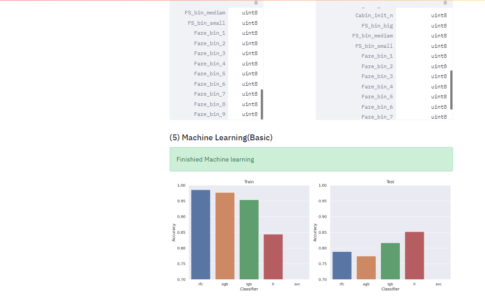
次回は、下記学習させる訓練データと、テストデータを作成して、前処理内容をグラフで確認できるWebアプリをStreamlitで実装してみたいと思います。
それではよいpython-streamlit ライフを!以下、関連記事となります。合わせてお読みいただけるお幸いです。





コメントを残す