

複数のデータファイルからあるデータを抽出して、新たなデータとしてまとめたいことはありませんでしょうか?
本記事は、csvファイルからデータを抽出して新しいcsvファイルを出力したい方におすすめの内容です。本記事を読むと、
- 複数のcsvファイルから同じ行列データを抽出
- 複数のcsvファイルから抽出したデータを新たなcsvファイルとして出力
ができるようになります。これをマスターすれば、大量のデータ処理が可能になるのでぜひ御覧ください。
python初心者のバランが、実務での実例に基づいて記載してますので、実務に活かしやすいです。
▼ Contents
0. 使用環境
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Python: Version 3.7.6 (64bit)
- pandas: Version 1.0.1
1. データ解析の全体図
本記事のデータサイエンスの紹介範囲を示します。
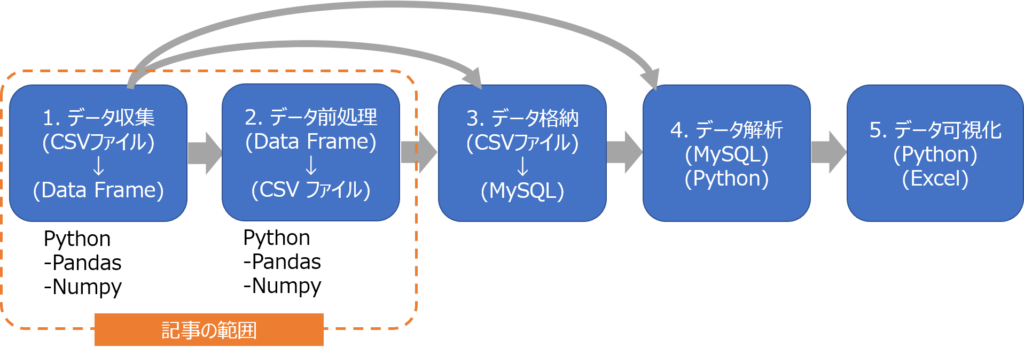
データサイエンスは主に5つのステージがあります。(図のようにステージを飛ばす場合もあります。図は一例です。)
- データ収集(データを集めて処理できる準備をする)
- データの前処理(データを格納もしくはデータを解析しやすいようにデータ配列を適切にする)
- データ格納(データを格納しておく)
- データ解析(実際のデータを用いてデータ分析・解析する)
- データ可視化(解析結果の意味がわかりやすいように可視化する)
本記事では、Pandasを用いた1. データ収集と2.データ前処理の範囲をカバーしています。
今回は”pandas”ライブラリを用いて、読み込んだ複数のCSVファイルの複数データの抽出から出力する方法を紹介します。
2. 実務で使えるデータ結合と出力
まず、本記事で使用するCSVが格納されているフォルダ構成例の全体図を見ていきましょう。
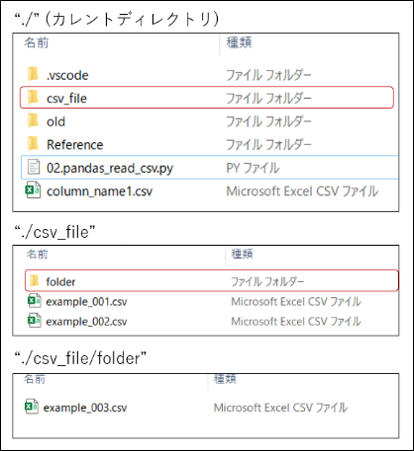
カレントディレクトリに”csv_file”フォルダを用意し、その直下に2つのCSVファイル(example_001.csv, example_002.csv)があります。さらに、”folder”があり、その直下に1つCSVファイル(example_003.csv)があります。
各CSVファイルの中身は以下です。
example_001.csv
1,11,21,31,41
2,12,22,32,42
3,13,23,33,43
4,14,24,34,44
5,15,25,35,45
example_002.csv
6,16,26,36,46
7,17,27,37,47
8,18,28,38,48
9,19,29,39,49
10,20,30,40,50
example_003.csv
101,111,121,131,141
102,112,122,132,142
103,113,123,133,143
104,114,124,134,144
105,115,125,135,145複数CSVファイルのデータを抽出して、新しいcsvファイルを出力してみましょう。サンプルコードは以下です。
""" 複数CSVのデータ抽出とファイル出力 """
import pandas as pd
from pathlib2 import Path
P = Path('./csv_file')
""" 再帰的に取得するファイル種類(csv) """
FILE_NAME = '**/*.csv'
CSV_FILES = P.glob(FILE_NAME)
OUTPUT = 'example_004.csv'
""" カラム(列)名 """
COLUMN_NAME = ['A', 'B', 'C', 'D', 'E']
""" データ格納先 """
LIST = []
def main():
""" 一括でフォルダ内のcsv読込=>データ抽出 """
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAME)
df2 = df1.loc[0, :]
LIST.append(df2)
"""" 格納されたデータを結合する """
df = pd.concat(LIST, axis=0)
print("-"*20)
print(OUTPUT)
print("-"*20)
print(df)
""" 新しいCSVファイルとして出力する """
df.to_csv(OUTPUT, index=True, encoding="utf-8")
if __name__ == '__main__':
main()pandasライブラリ、Pathライブラリによる複数のCSV読み取り方法や、”loc”や”iloc”によるデータのスライス方法が不明な方は、前回の記事も合わせてお読みいただけると本記事の理解がスムーズかと思います。
まず、以下のコードで出力するcsvファイル名(末尾に”.csv”をつけるのを忘れない)と、複数のcsvから抽出したデータをリスト型として格納する箱を作成しておきます。
""" 出力ファイルパスおよびファイル名 """
OUTPUT = 'example_004.csv'
""" データ格納先 """
LIST = []次に、以下の操作を行います
- PATHライブラリで取得しているCSV_FILESから読み込んでいるcsvファイルを”df1″に格納しています。
- 必要なデータを”loc”もしくは”iloc”でデータをスライスします。
- スライスされたデータは”df2″に渡します。(ここではrow=”0″を抽出します。)
- “df2″のデータを”append”関数を用いて、先ほど作成した”LIST”に格納します。
そして、for文により読み込んだcsvファイルごとに上記の1~4の操作を繰り返します。
""" 一括でフォルダ内のcsv読込=>データ抽出 """
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAME)
df2 = df1.loc[0, :]
LIST.append(df2)まだ、”LIST”に格納されたデータは、それぞれ独立したリストとして格納されています。(データ形式を確認する場合は、print関数でご確認ください。)
そこで、pandasライブラリの”concat”関数を用いて”LIST”のデータをすべて結合し、”df”に格納します。”concat”関数のインデントにご注意ください。“concat”関数は上記for文の処理が完了したあとに実行される必要があります。
そのため、for文と”concat”関数処理のインデントは等しくなります。
"""格納されたデータを結合する """
df = pd.concat(LIST, axis=0)第2引数の”axis”は結合する方向を定めます。デフォルトは”axis=0″で、縦方向にデータを結合します。横方向に結合したい場合は、”axis=1″を指定します。
格納されたdfをprint関数で見てみましょう。
-----------------------------
example_004.csv (axis=0の場合)
-----------------------------
A 1
B 11
C 21
D 31
E 41
A 6
B 16
C 26
D 36
E 46
A 101
B 111
C 121
D 131
E 141
Name: 0, dtype: int64-----------------------------
example_004.csv (axis=1の場合)
-----------------------------
0 0 0
A 1 6 101
B 11 16 111
C 21 26 121
D 31 36 131
E 41 46 141データが結合されていることが確認できますね。
そして、最後に結合されたデータを新しいcsvファイルとして出力します。出力先は、先ほど設定した”OUTPUT”で指定したパス先およびファイル名となります。
“index”を残したまま、csvファイルを出力する場合は、第2引数”index”を”True”にします。
""" 出力ファイルパスおよびファイル名 """
OUTPUT = 'example_004.csv'
""" 新しいCSVとして出力する """
df.to_csv(OUTPUT, index=True, encoding="utf-8")保存先に”OUTPUT”で指定した名前のcsvファイルが作成されているはずです。保存先のパスなどは適宜変更していただければと思います。
3. まとめ
今回の記事は、pythonによる複数csvファイルのデータを抽出し、一つのデータとして結合、新しいcsvファイルとして出力する方法をまとめました。
データ構造が同じCSVファイルであれば、複数のデータを一括で抽出し、まとめて出力することができます。
この操作により、大量の同じデータ構造を処理して、データを可視化する際に非常に便利なので、使いこなせると業務が捗りますね。
次回は、同じデータのみを抽出し、複数の新たなcsvファイルを出力する際に、csvファイル名をそれぞれ別名で出力する方法を記事にする予定です。
それでは、良いpythonライフを!



[…] 【Python入門】複数csvデータ結合と出力【初心者向け】 […]