

この記事では、データ分析や解析では必須なPython-pandasによるデータ読み込み方法を記載しています。実務経験に基づいて記載ですので、すぐに実務に活かせます。
▼ Contents
使用環境
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Python: Version 3.7.6 (64bit)
1. データ分析・解析の全体図
本記事のデータサイエンスの紹介範囲を示します。
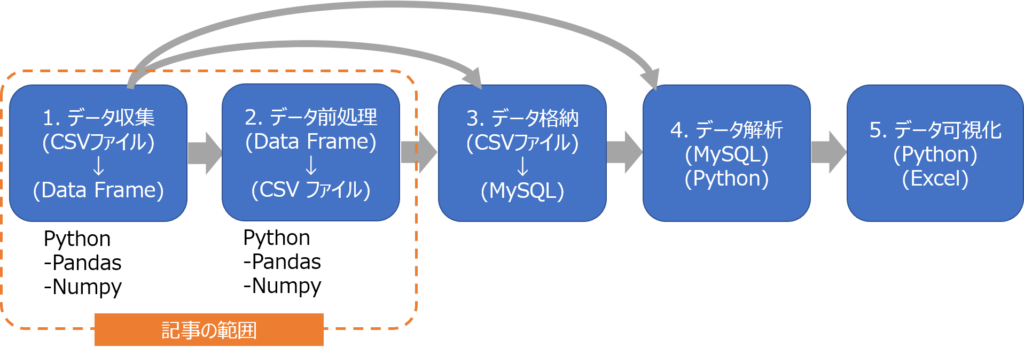
データサイエンスは主に5つのステージがあります。(図のようにステージを飛ばす場合もあります。図は一例です。)
- データ収集(データを集めて処理できる準備をする)
- データの前処理(データを格納もしくはデータを解析しやすいようにデータ配列を適切にする)
- データ格納(データを格納しておく)
- データ解析(実際のデータを用いてデータ分析・解析する)
- データ可視化(解析結果の意味がわかりやすいように可視化する)
本記事では、Pandasを用いた1. データ収集と2.データ前処理の範囲をカバーしています。今回はその中でも一番最初に行うPandasライブラリを用いたCSVファイルの読み込み方法を紹介します。
それでは、やっていきましょう。
2. pandasとは
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。特に、数表および時系列データを操作するためのデータ構造と演算を提供する
Wikipedia: https://ja.wikipedia.org/wiki/Pandas
pandasの特徴
・データ操作のための高速で効率的なデータフレーム (
DataFrame) オブジェクト・メモリ内のデータ構造とその他のフォーマットのデータ間で相互に読み書きするためのツール群。フォーマット例: CSV、テキストファイル、Excel、SQLデータベース、HDF5フォーマットなど
・かしこいデータのアライメントおよび統合された欠損値処理 etc
Wikipedia: https://ja.wikipedia.org/wiki/Pandas
簡単に言うと、Pythonのライブラリ(機能みたいなもの)のひとつで、データの形を高速で効率的に操作しやすい形(データフレーム: Data Frame)に変換するツールです。
このツールはPythonの機能の特徴の一つで、CSV読み込みもこのライブラリを用いるので、ぜひ覚えてもらいたいライブラリです。
3. CSVとは
comma-separated values(略称:CSV)は、テキストデータをいくつかのフィールド(項目)に分け、区切り文字であるカンマ「
Wikipedia,」で区切ったデータ形式。拡張子は.csv。
ざっくりいうと、データの切り分けに「カンマ:”, “」を用いたデータ形式となります。
以下の内容がCSVのデータ形式例となります。数字を”,”で区切っていますね。(このファイルは本記事の例題としても使用します。)
1,11,21,31,41
2,12,22,32,42
3,13,23,33,43
4,14,24,34,44
5,15,25,35,454. 実務で使えるCSV読み込み方法
まずはプログラムの全体を見ていきましょう。今回はCSVを読み込んでprint関数でCSVの中身を見ています。(“#”の後ろにあるコメントはプログラムに影響が出ないようになっています。)
– CSV読み込みの基本
""" pandasのインポート """
import pandas as pd
""" CSVファイルのパス """
csv_file = 'csv_file/example_001.csv'
def main():
""" メインの処理 """
df1 = pd.read_csv(csv_file)
print('結果1')
print(df1)
if __name__ == '__main__':
main()では、具体的に各行の内容を見ていきましょう!
""" pandasのインポート """
import pandas as pd一行目で”pandas”のライブラリを”pd”として読み込んでいます。この読み込みにより、”pandas”のライブラリが使用可能となります。
""" CSVファイルのパス(カレントディレクトリ内のフォルダ) """
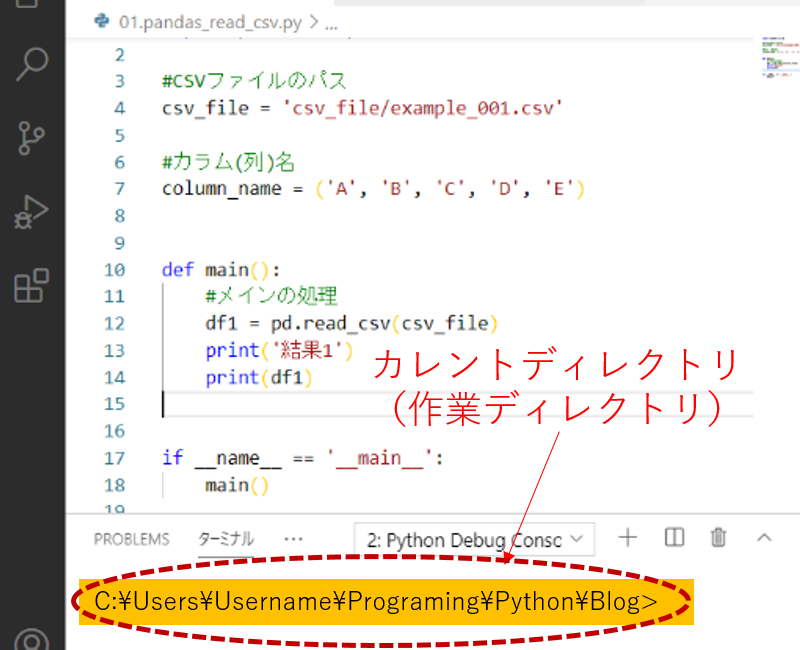
csv_file = 'csv_file/test1.csv'CSVファイルへのパスを指定します。パスは絶対パスかカレントディレクトリ(作業ディレクトリ)からの相対パスで指定してください。この”csv_file”は後ほど使用します。
なお、カレントディレクトリ(作業ディレクトリ)がわからない場合は、VS codeの”ターミナル”画面のパスを確認してみてください。(C:\Users\username\Programing\Python\Blogは一例です。環境によって異なります。)
""" CSVファイルデータをData Frameに変換 """
df1 = pd.read_csv(csv_file)pandasライブラリのread_csvを用いて「csv_file=’csv_file/test1.csv’」のCSVファイルのデータを読み込みます。
そしてデータフレーム形式に変換して、「df1」にデータを格納します。(df1はData Frame1の略称です。名称は各個人で設定可能です。)
このdf1データをprint関数で出力してみます。
""" pandasのインポート """
import pandas as pd
""" CSVファイルのパス """
csv_file = 'csv_file/example_001.csv'
""" CSVファイルデータをData Frameに変換 """
df1 = pd.read_csv(csv_file)
print('結果1')
print(df1)
if __name__ == '__main__':
main()
"""
結果1
1 11 21 31 41 <=カラム名
0 2 12 22 32 42
1 3 13 23 33 43
2 4 14 24 34 44
3 5 15 25 35 45
"""表示できました。ただ、1行目がカラム名になってしまいました。カラム名は今後のデータ前処理やデータ解析の際に、データの位置情報を探す重要な項目です。そこで、カラム名を自動的に数値で与えてくれるのが次のコードとなります。
– CSV読み込み時にheaderを指定する方法
pd.read_csv()に”header=None”を追加することで、カラム名に数値を指定できます。
""" pandasのインポート """
import pandas as pd
""" CSVファイルのパス """
csv_file = 'csv_file/example_001.csv'
""" CSV読み込み時にheaderを指定 """
df2 = pd.read_csv(csv_file, header=None)
print('結果2')
print(df2)
if __name__ == '__main__':
main()
"""
結果2
0 1 2 3 4 <=カラム名
0 1 11 21 31 41
1 2 12 22 32 42
2 3 13 23 33 43
3 4 14 24 34 44
4 5 15 25 35 45
"""– カラム(列)名を自分で指定する方法
カラム名は自分でも設定できます。以下のコードのように”column_name”を作成してみましょう。”,”で区切ることを忘れないように!
""" カラム(列)名 """
column_name = ('A', 'B', 'C', 'D', 'E')pd.read_csv()に”names”を追加して、先ほど設定した”column_name”を指定することで、カラム名を”column_name”にすることができます。
""" pandasのインポート """
import pandas as pd
""" CSVファイルのパス """
csv_file = 'csv_file/example_001.csv'
""" カラム(列)名 """
column_name = ('A', 'B', 'C', 'D', 'E')
""" カラム(列)名を自分で指定 """
df3 = pd.read_csv(csv_file, names=column_name)
print('結果3')
print(df3)
"""
結果3
A B C D E <=カラム名
0 1 11 21 31 41
1 2 12 22 32 42
2 3 13 23 33 43
3 4 14 24 34 44
4 5 15 25 35 45
"""指定したカラム名を表示できました!
5. まとめ
今回は、pandasを用いたCSVの読み込み方法の基礎をまとめ、まずはひとつのCSVを読み込んでいきました。
次は複数のCSVファイルを読み込んでいきます。
ご覧頂きありがとうございました。
補足 if __name__ == ‘__main__’とは
if __name__ == '__main__'は「該当のファイルがコマンドラインからスクリプトとして実行された場合にのみ以降の処理を実行する」という意味。他のファイルからインポートされたときは処理は実行されない。「
Pythonのif __name__ == ‘__main__’の意味と使い方__name__に格納されている値が'__main__'という文字列である場合に以降の処理を実行する」という単なるif文なので、__name__と'__main__'の意味が分かれば理解しやすい。
本記事での意味は、「__name__に格納されている値が'__main__'という文字列である場合にmain()の処理を実行する」となります。
以下コードのように削除しても、プログラムは動作します。
""" pandasのインポート """
import pandas as pd
""" CSVファイルのパス """
csv_file = 'csv_file/example_001.csv'
""" カラム(列)名 """
column_name = ('A', 'B', 'C', 'D', 'E')
""" メインの処理 """
df3 = pd.read_csv(csv_file, names=column_name)
print('結果3')
print(df3)
"""
結果3
A B C D E <=カラム名
0 1 11 21 31 41
1 2 12 22 32 42
2 3 13 23 33 43
3 4 14 24 34 44
4 5 15 25 35 45
"""まずはpythonのおまじないのようなものと理解いただければ大丈夫ですが、詳しく知りたい方は以下の記事をご参考ください。
https://note.nkmk.me/python-if-name-main/
それでは良いpythonライフを!






[…] Python入門~PandasによるCSV読み取り~【初心者向け】 […]
[…] Python入門~実務で使えるPandasによるCSV読み取り~【未経験OK】 […]