

前回から、Dockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。
今回から、趣旨である自身のTwitterデータのグラフから、どんなTweetが数値的に人気があったのか調べていきます。
本記事を読むと、
- 自身のTweetで高評価なものがわかる
- 高評価Tweetを参考にして、次のTweet内容に生かせる(かも)
- 分析用のサンプルコード(Python)を使用できる
ので、ので、ぜひ最後までご覧いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでみてください。それではやっていましょう!
▼ Contents
1. 解析用データの準備
環境構築、マルチインデックス化によるグラフ用Twitterデータの準備が終わってない方は、下記記事をご参考いただけると幸いです。

時系列のマルチインデックス化は、時間軸を用いるグラフ化には便利な機能です。ぜひ、ご参考いただけると幸いです。
以下の本記事内容は、Docker環境で構築したJupyterlabをベースに作成しています。予めご了承ください。
使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
ファイルフォルダー構成は以下です。
.
|-- docker-compose.yml
`-- python_app
|-- Dockerfile
`-- jupyter_work
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_UserName_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
|-- evaluation_analytics.py
|-- graph_analytics.py
`-- time_analytics.pyDockerfileは以下のようにして、AnacondaをDockerコンテナ内に用意します。
#Dockerfile
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y \
sudo \
wget \
vim
#Anacondaのインストール
WORKDIR /opt
RUN wget https://repo.continuum.io/archive/Anaconda3-2020.07-Linux-x86_64.sh && \
sh /opt/Anaconda3-2020.07-Linux-x86_64.sh -b -p /opt/anaconda3 && \
rm -f Anaconda3-2020.07-Linux-x86_64.sh
ENV PATH /opt/anaconda3/bin:$PATH
WORKDIR /
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--allow-root", "--LabApp.token=''"]また、docker-compose.ymlは以下のようにしています。
#docker-compose.yml
version: '3'
services:
app:
build:
context: ./python_app
dockerfile: Dockerfile
container_name: app
ports:
- '5551:8888'
volumes:
- '.:/work'
tty: true
stdin_open: true2. ‘Engagement’データを視覚的に確認する
今回は、前回作成したTweetごとの傾向、特に’Engagement’を確認していきます。まずは、以下のコードを入力してみてください。
""" Twitter_analytics.ipynb """
import graph_analytics as ga
""" 4.データ分析編 """
ga.bar_hist_single(twitter_df, 'Engagement')""" graph_analytics.py """
import matplotlib.pyplot as plt
def bar_hist_single(df, column='Engagement'):
fig, axes = plt.subplots(2, 1, figsize=(20,8))
axes[0].bar(df.index, column, data=df, label=column)
axes[0].set_title(column)
axes[0].twinx().plot(df.index, 'Engagement_Ratio', color='r', data=df, linestyle='--', marker='o')
axes[1].hist(column, data=df, label=column, bins=50)
axes[1].set_xlabel(column)
axes[1].set_title('Histogram')
plt.plot()上記コードを入力すると、axes[0]にTwitterデータのTweetごとの’Engagement’の棒グラフと’Engagement_Ratio’の折れ線グラフ、axes[1]に’Engagement’のヒストグラムが作成されます。
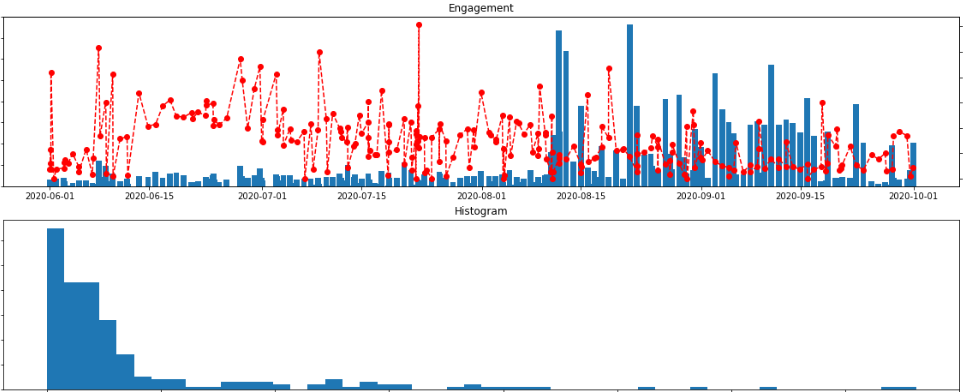
グラフを見ると、多くのTweetは’Engagement’数は低いですが、一部のTweetは’Engagement’数が高くなっています。
次に、’Engagement’の構成要素である[“RT”, “Return”, “Good”, “User_Click”, “URL_Click”, “Hash_Click”, “Detail_Click”]の各月ごとの合計数を見てみます。
以下のコードを入力してみてください。
""" Twitter_analytics.ipynb """
twitter_df_engagement = m_twitter_df.iloc[:, 4:]
ga.bar_bottom_column(twitter_df_engagement, 0.5)def bar_bottom_column(df, width=0.5):
bottom = 0
fig, axes = plt.subplots(1, 1, figsize=(20,5))
for i in range(len(df)):
axes.bar(df.columns, df.iloc[i], bottom=bottom, width=width)
bottom += df.iloc[i]
axes.set_xlabel('Item')
axes.set_title('Count')
axes.legend(df.index)
fig.tight_layout()
plt.plot()以上のコードを入力すると、Twitterデータの月ごとの’Engagement’の構成要素の積み上げ棒グラフが作成されます。
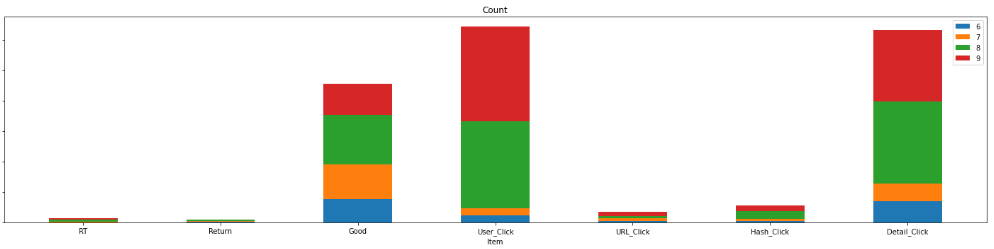
このグラフを見ると、[“Good”, “User_Click”, “Detail_Click”]が’Engagement’数に大きく影響してそうです。各項目の相関関係はどの様になっているでしょうか、確認してみましょう。
なお、相関係数に関しては以下をご参考するとわかりやすいと思います。
相関係数とは何か。その求め方・公式・使い方と3つの注意点
相関関数を確認するため、以下のコードを入力してみましょう。
import evaluation_analytics as ea
ea.corr_df(twitter_df)""" evaluation_analytics.py """
def corr_df(df):
fig, axes = plt.subplots(figsize=(20,5))
df_corr = df.corr()
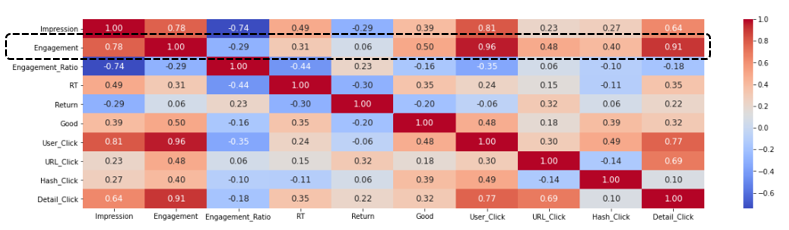
sns.heatmap(df_corr, cmap='coolwarm', annot=True, annot_kws={'size': 12}, fmt='.2f')以上のコードを入力すると、各項目の相関関数が表示されます。
相関関数がよくわからない方は、こちらのブログが非常にわかりやすいかなともいます。
【Pythonで学ぶ】相関係数をわかりやすく解説【データサイエンス入門:統計編11】
相関係数を見ると、’Engagement’は[“User_Click”, “Detail_Click”]との相関が強そう(1に近い)ですね。一方、”Good”は相関関数が0.5なのでそこまで、’Engagement’に影響しているとは言いづらそうです。
以上から、私のTweetで’Engagement’を増やすには、[“User_Click”, “Detail_Click”]を多く得ているTweetを参考にすると良さそうです。
3. 特定項目の値が上位であるTweetを取得する
[“User_Click”, “Detail_Click”]を多く得ているTweetを抽出するために、以下のコードを入力してみます。dict_analytics = {'User_Click': 'eval_user', 'Detail_Click': 'eval_detail'}
percent = 10
for col, eva in dict_analytics.items():
twitter_df = ea.evaluation_percent(twitter_df, column=col, evaluation=eva, percent=percent)""" evaluation_analytics.py """
def evaluation_percent(df, column='Engagement', evaluation='evaluation', percent=50):
per = df[column].quantile(q=[(100-percent)/100]).iloc[0]
df[evaluation] = df[column].apply(lambda x: 'Top{}%'.format(percent) if x >= per else 'Less{}%'.format(percent))
return dfpercent=10は上位何%のTweetを取得するかを決定できます。今回は上位10%を対象としました。
上記のコードで、特定項目(今回は”User_Click”と”Detail_Click”)の上位10%とその他を評価する新たなデータフレームを作成します。
twitter_dfを見てみましょう。以下のように’eval_user’と’eval_detail’のカラムが増えていると思います。なお、’Top10%’が各項目上位10%のTweet、それ以外は’Less10%’と表示するようにしています。

では、’eval_user’と’eval_detail’の評価基準を用いて、”User_Click”と”Detail_Click”がともに上位10%であるTweetを抽出していきます。
以下のコードを入力してみてください。各項目の’Top10%’であるTweetのみを抽出します。
great_twitter_df = twitter_df[(twitter_df['eval_user'] =='Top{}%'.format(percent)) & \
(twitter_df['eval_detail'] =='Top{}%'.format(percent))]great_twitter_dfは、”User_Click”と”Detail_Click”がともに上位10%であるTweetデータとなります。
great_twitter_dfに記載されているTweetを参考にすると、’Engagement’を多く得られる可能性が高いと考えられます。
以上が数値から見た高評価Tweetを抽出する方法のひとつとなります。
4. サンプルコードとまとめ
以上の内容のサンプルコードをまとめたものは以下となります。
ファイルフォルダー構成は以下です。
.
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_BaranGizagiza_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
|-- graph_analytics.py
|-- evaluation_analytics.py
`-- time_analytics.py各ファイルは以下となります。
""" Twitter_analytics.ipynb """
import data_base_analytics as da
import time_analytics as ta
import graph_analytics as ga
import evaluation_analytics as ea
percent = 10
def main():
""" main """
"""1.準備編 """
twitter_data_path = da.data_path()
twitter_df = da.data_df(twitter_data_path)
twitter_df = da.data_en(twitter_df)
twitter_df = da.data_time(twitter_df)
""" 2.時系列編 """
yqmwwd_twitter_df = ta.yqmwwd_df(twitter_df)
w_twitter_df = ta.groupby_df(yqmwwd_twitter_df, 'week', 'sum')
w_twitter_df['Engagement_Ratio'] = ta.engagement_ratio(w_twitter_df)
m_twitter_df = ta.groupby_df(yqmwwd_twitter_df, 'month', 'sum')
m_twitter_df['Engagement_Ratio'] = ta.engagement_ratio(m_twitter_df)
""" 3.グラフ化編 """
columns = twitter_df.columns.to_list()
ga.bar_plot(w_twitter_df, columns)
""" 4.数値分析編 """
ga.bar_hist_single(twitter_df, 'Engagement')
ga.bar_bottom_column(m_twitter_df.iloc[:, 3:], 0.5)
ea.corr_df(twitter_df)
dict_analytics = {'User_Click': 'eval_user', 'Detail_Click': 'eval_detail'}
for col, eva in dict_analytics.items():
twitter_df = ea.evaluation_percent(twitter_df, column=col, evaluation=eva, percent=percent)
great_twitter_df = twitter_df[(twitter_df['eval_user'] =='Top{}%'.format(percent)) & \
(twitter_df['eval_detail'] =='Top{}%'.format(percent))]
""" data_base_analytics.py """
"""1.準備編 """
from pathlib import Path
import pandas as pd
Data_path = './data'
Data_file_name = '*ja.csv'
Encode = 'CP932'
def data_path():
return Path(Data_path ).glob(Data_file_name)
def data_df(file_path):
LIST = [pd.read_csv(file, encoding=Encode) for file in file_path]
df = pd.concat(LIST)
return df
def data_en(df):
df = df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
return df
def data_time(df):
df['Time'] = pd.to_datetime(df['Time'].apply(lambda x: x[:-5]))
df = df.set_index('Time').sort_index()
return df""" time_analytics.py """
""" 2.時系列編 """
import datetime
def yqmwwd_df(df):
yqmwwd_df = df.set_index([df.index.year, df.index.quarter,\
df.index.month, df.index.week,\
df.index.weekday, df.index.day, df.index])
yqmwwd_df.index.names = ['year', 'quarter', 'month', 'week', 'weekday', 'day', 'date']
return yqmwwd_df
def groupby_df(df, level_time='week', agg_iterable='sum'):
groupby_df = df.groupby(level=level_time).agg(agg_iterable)
return groupby_df
def engagement_ratio(df):
return df['Engagement'] / df['Impression']""" graph_analytics.py """
""" 3.グラフ化編 """
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
Colors = mcolors.TABLEAU_COLORS.items()
def bar_plot_multi(df, columns):
fig, axes = plt.subplots(10, 1, figsize=(15,30))
for idx, (color, rgb) in enumerate(Colors):
axes[idx].bar(df.index, columns[idx+1], color=rgb, data=df, label=columns[idx+1])
axes[idx].set_xlabel('Time')
axes[idx].set_ylabel(columns[idx+1])
axes[idx].set_title(columns[idx+1])
fig.tight_layout()
plt.plot()
""" 4.数値分析編 """
def bar_hist_single(df, column='Engagement'):
fig, axes = plt.subplots(2, 1, figsize=(20,8))
axes[0].bar(df.index, column, data=df, label=column)
axes[0].set_title(column)
axes[0].twinx().plot(df.index, 'Engagement_Ratio', color='r', data=df, linestyle='--', marker='o')
axes[1].hist(column, data=df, label=column, bins=50)
axes[1].set_xlabel(column)
axes[1].set_title('Histogram')
plt.plot()
def bar_bottom_column(df, width=0.5):
bottom = 0
fig, axes = plt.subplots(1, 1, figsize=(20,5))
for i in range(len(df)):
axes.bar(df.columns, df.iloc[i], bottom=bottom, width=width)
bottom += df.iloc[i]
axes.set_xlabel('Item')
axes.set_title('Count')
axes.legend(df.index)
fig.tight_layout()
plt.plot()""" evaluation_analytics.py """
""" 4.数値分析編 """
import matplotlib.pyplot as plt
import seaborn as sns
def evaluation_percent(df, column='Engagement', evaluation='evaluation', percent=50):
per = df[column].quantile(q=[(100-percent)/100]).iloc[0]
df[evaluation] = df[column].apply(lambda x: 'Top{}%'.format(percent) if x >= per else 'Less{}%'.format(percent))
return df
def corr_df(df):
fig, axes = plt.subplots(figsize=(20,5))
df_corr = df.corr()
sns.heatmap(df_corr, cmap='coolwarm', annot=True, annot_kws={'size': 12}, fmt='.2f')以上のファイルを用意して、jupyterlab上でmain()を呼び出した後に、great_twitter_dfを呼び出せば、高評価Tweetを抽出できると思います。
私も詰まったところが、pythonファイルを更新すると、モジュールを読み込む際は、「カーネルを再起動するか、import libを使う」必要があります。詳しくは以下のサイトに記載されているので、ご参考いただけると幸いです。
【Python】Jupyter notebookを使うときに守るべきPythonの作法2選
次回は、評価でグラフを分類する手法を用いて、詳細な解析をしていく予定です。
また、今後の分析内容としては
- MySQLとの連携
- 統計学とTwitterデータをからめる
- Tweetによる各項目の予測値
などを予定しています。乞うご期待ください。それでは、よいPythonライフを!!
本記事に関連する過去の投稿は以下です。ご覧いただけると幸いです。


[…] […]