

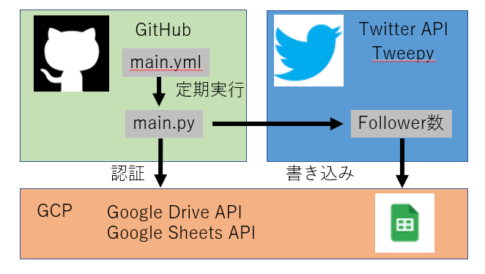
前回から、Dockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。特に今回は、Twitterデータをグラフ化してみようと思います。
本記事を読むと、
- グラフを用いてTwitterアナリティクスの見える化ができる
- 分析用のサンプルコード(Python)を使用できる
ので、ぜひ最後までご覧いただけると幸いです。
なお、サンプルコードは最後に記載していますので、サンプルコードだけほしい方は、目次リンクで飛んでいただけると幸いです。
それではやっていましょう!
▼ Contents
1. 解析用データの準備(前回記事)
環境構築、マルチインデックス化によるグラフ用Twitterデータの準備が終わってない方は、下記記事をご参考ください。

時系列のマルチインデックス化は、時間軸を用いるグラフ化には便利な機能です。ぜひ、ご参考いただけると幸いです。
以下の本記事内容は、Docker環境で構築したJupyterlabをベースに作成しています。予めご了承ください。使用環境概要は以下となります。
- ホストOS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Docker image: ubuntu:18.04
- Anaconda: Anaconda3-2020.07-Linux-x86_64
- Python: Version 3.8.3 (64bit)
2. 時系列をベースにTwitterデータの棒グラフを作成する(初級編)
今回は、前回作成した時間ごと、1週間ごとおよび1ヶ月毎のTwitterデータの棒グラフを作成していきます。まずは、以下のコードを入力しましょう。
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 1, figsize=(20,5))まずは、図を作成する上で欠かせないmatplotlibのモジュールをインポートします。
次にグラフを記載先を設定するためにsubplotsを用います。
plt.subplotsは、複数のグラフを一度に記載したときに便利です。figsize=(20, 5)は見たとおり、グラフのサイズを指定できます。
本記事ではとりあえず、(20, 5)とします。ご自身の環境に合わせてfigサイズは変更してみてください。
plt.subplots(1, 1)はグラフを記載する行列座標を表しています。例えば(1, 1)だとfigとaxesは以下のような図1のイメージになります。(最初の座標数値は0であることに注意する)

(2, 2)だとfigとaxesは以下のような図のイメージになります。
グラフの元ができたので、グラフを記載していきましょう。今回は各twitterデータの数値のトレンドを見たいので、棒グラフにしてみます。以下のコードを入力してみてください。
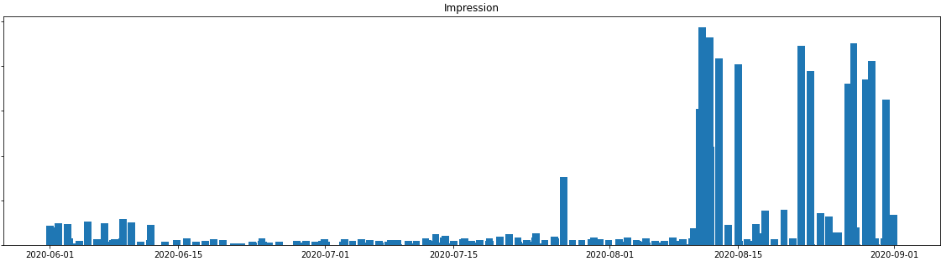
axes.bar(twitter_df.index, "Impression", data=twitter_df, label="Impression")
axes.set_xlabel('Time')
axes.set_title("Impression")“Impression”の1日あたりの棒グラフができているはずです。
また、以下のコードを入力してみてください。w_twitter_dfは1週毎の合計データになります。
axes.bar(w_twitter_df.index, "Impression", data=w_twitter_df, label="Impression")
axes.set_xlabel('Week')
axes.set_title("Impression")“Impression”の1週間あたりの棒グラフができているはずです。このあたりでマルチインデックス化の効果が見えてきましたね。

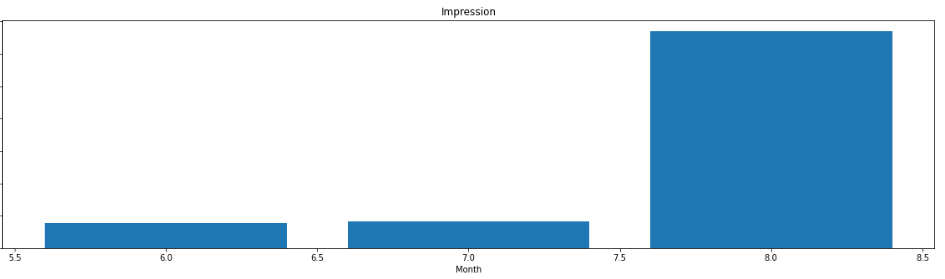
もちろん、下記のコードも動作します。m_twitter_dfは1ヶ月毎の合計データになります。
axes.bar(m_twitter_df.index, "Impression", data=m_twitter_df, label="Impression")
axes.set_xlabel('Month')
axes.set_title("Impression")”Impression”の1ヶ月間あたりの棒グラフができているはずです。マルチインデックス化を使えば、上記のよう簡単に集計の棒グラフが作成できちゃいます!
便利ですね!表示したいグラフを変更したい場合は、以下のように参照するコラムを変更してみてください。
axes.bar(twitter_df.index, "Engagement", data=twitter_df, label="Engagement")以上がグラフ作成の初級編となります。
3. 時系列をベースにTwitterデータの棒グラフを複数同時に作成する(応用編)
さて、疑問に思った方もいるかも知れません。
「複数のグラフを同時に作成できたほうが便利じゃないだろうか。。。」
そのとおりです。以下で作成していきましょう。下準備として、twitterデータのカラムを確認します。以下の入力してみてください。
columns = twitter_df.columns.to_list()columnsを確認すると以下のリストが得られると思います。(‘Time’はインデックス化したのでカラムにはありません)

カラムリストを確認すると、”Tweet”を除く10項目は棒グラフが作成できそうです。個人的に10個のグラフが同じ色だと味気ないので、色分けしたいと思います。今回は、Tableauのカラーパレット(Tableau 10)の色を使用してみます。
詳しい色の種類などは以下のサイトに記載されているので、興味ある方は確認してみてください。
matplotlibでTableau風の色を使う
Tableau 10をインポートするため、以下のコードを記載していきます。
import matplotlib.colors as mcolors
Colors = mcolors.TABLEAU_COLORS.items()これで10色を用意できたので、グラフを作成していきましょう!以下のコードを記載してみてください。これは1週ごとのTweetデータの合計値(Engagement_ratioは比率計算済)を表示できます。
fig, axes = plt.subplots(10, 1, figsize=(15,30))
for idx, (color, rgb) in enumerate(Colors):
axes[idx].bar(w_twitter_df.index, columns[idx+1], color=rgb, data=w_twitter_df, label=columns[idx+1])
axes[idx].set_xlabel('Week')
axes[idx].set_title(columns[idx+1])
fig.tight_layout()
plt.plot()for文で複数グラフを作成するので、enumerate関数でインデックス番号(idx)も取得し、axes[idx]の変数とすることで複数グラフを一気に作成しています。
また、columnsの情報をデータフレーム列選択や軸名、タイトル名に使用しています。注意点は、columns[0] = “Tweet”の情報はグラフ化できないため、スキップされます。そのため、idxとcolumnsの列番号を合わせるため、columns[idx+1]としています。
上記のコードを実行すると、以下のような色別のグラフが作成されているはずです。
あとは、日ごとや月ごとのデータをグラフ化したい場合は、columns情報は同じため、選択するデータフレームや横軸名だけ変更すればOKです。以下は月ごとの棒グラフを作成するサンプルコードになります。
ほとんど変化なし!(w_twitter_df → m_twitter_df)
fig, axes = plt.subplots(10, 1, figsize=(15,30))
for idx, (color, rgb) in enumerate(Colors):
axes[idx].bar(m_twitter_df.index, columns[idx+1], color=rgb, data=m_twitter_df, label=columns[idx+1])
axes[idx].set_xlabel('Month')
axes[idx].set_title(columns[idx+1])
fig.tight_layout()
plt.plot()これで、Twutterデータのすべての数値データを同時に棒グラフで表示することができました。
4. (補足) 棒グラフに折れ線グラフを追加して表示する
棒グラフとは別のグラフを2軸表示したいこともあるかなと思います。
ここでは、Twitterデータの”Impression”(棒グラフ)と”Enagagement_ratio”(折れ線グラフを同じグラフ上に表示していきます。
早速ですが、以下のコードを入力してみてください。
axes[0].twinx().plot(w_twitter_df.index, columns[3], color='r', data=w_twitter_df, label="Enagagement=ratio")
fig.tight_layout()
plt.plot()twinx()は別軸でプロットしたいときに使用します。なお、axes[0]は”impression”のデータです。また、columns[3]=”Engagement_ratio”です。
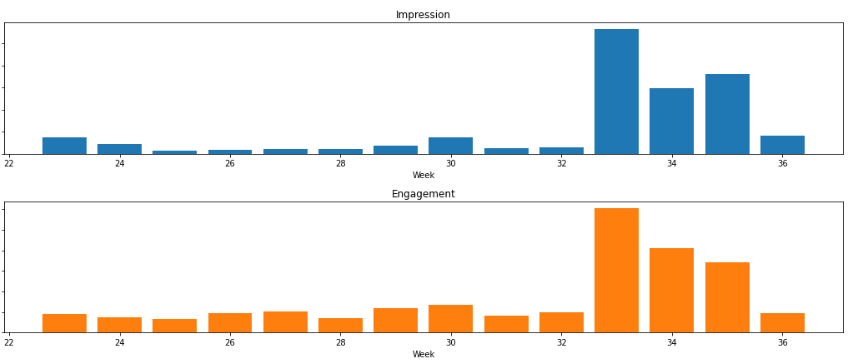
以下のようなグラフが表示されると思います。
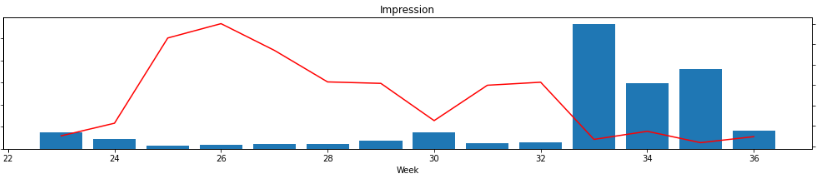
青色の棒グラフは、”Impression”を表し、赤色の折れ線は”Enagagement_ratio”を表しています。
今回は棒グラフと折れ線の組み合わせでしたが、他の組み合わせも考えられるので、是非試してみてください!
5. サンプルコードとまとめ
以上の内容をまとめたサンプルコードは以下です。
ただ、前回からの続きのため、定義関数が多くコードが長くなってきたので、関数化およびPythonファイルを作成し、モジュールとして呼び込んでいます。
ファイルフォルダー構成は以下です。
.
|-- Twitter_analytics.ipynb
|-- data
| `-- tweet_activity_metrics_BaranGizagiza_YYYYMMDD_YYYYMMDD_ja.csv
|-- data_base_analytics.py
|-- graph_analytics.py
`-- time_analytics.py各ファイルは以下となります。
""" Twitter_analytics.ipynb """
import data_base_analytics as da
import time_analytics as ta
import graph_analytics as ga
def main():
""" main """
"""1.準備編 """
twitter_data_path = da.data_path()
twitter_df = da.data_df(twitter_data_path)
twitter_df = da.data_en(twitter_df)
twitter_df = da.data_time(twitter_df)
""" 2.時系列編 """
yqmwwd_twitter_df = ta.yqmwwd_df(twitter_df)
w_twitter_df = ta.groupby_df(yqmwwd_twitter_df, 'week', 'sum')
w_twitter_df['Engagement_Ratio'] = ta.engagement_ratio(w_twitter_df)
m_twitter_df = ta.groupby_df(yqmwwd_twitter_df, 'month', 'sum')
m_twitter_df['Engagement_Ratio'] = ta.engagement_ratio(m_twitter_df)
""" 3.グラフ化編 """
columns = twitter_df.columns.to_list()
ga.bar_plot(w_twitter_df, columns)""" data_base_analytics.py """
"""1.準備編 """
from pathlib import Path
import pandas as pd
Data_path = './data'
Data_file_name = '*ja.csv'
Encode = 'CP932'
def data_path():
return Path(Data_path ).glob(Data_file_name)
def data_df(file_path):
LIST = [pd.read_csv(file, encoding=Encode) for file in file_path]
df = pd.concat(LIST)
return df
def data_en(df):
df = df[["ツイート本文","時間","インプレッション",\
"エンゲージメント","エンゲージメント率","リツイート", \
"返信","いいね","ユーザープロフィールクリック",\
"URLクリック数","ハッシュタグクリック","詳細クリック"]]
df.columns = ["Tweet", "Time", "Impression", "Engagement", \
"Engagement_Ratio", "RT", "Return", "Good", "User_Click", \
"URL_Click", "Hash_Click", "Detail_Click"]
return df
def data_time(df):
df['Time'] = pd.to_datetime(df['Time'].apply(lambda x: x[:-5]))
df = df.set_index('Time').sort_index()
return df""" time_analytics.py """
""" 2.時系列編 """
import datetime
def yqmwwd_df(df):
yqmwwd_df = df.set_index([df.index.year, df.index.quarter,\
df.index.month, df.index.week,\
df.index.weekday, df.index.day, df.index])
yqmwwd_df.index.names = ['year', 'quarter', 'month', 'week', 'weekday', 'day', 'date']
return yqmwwd_df
def groupby_df(df, level_time='week', agg_iterable='sum'):
groupby_df = df.groupby(level=level_time).agg(agg_iterable)
return groupby_df
def engagement_ratio(df):
return df['Engagement'] / df['Impression']""" graph_analytics.py """
""" 3.グラフ化編 """
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
Colors = mcolors.TABLEAU_COLORS.items()
def bar_plot(df, columns):
fig, axes = plt.subplots(10, 1, figsize=(15,30))
for idx, (color, rgb) in enumerate(Colors):
axes[idx].bar(df.index, columns[idx+1], color=rgb, data=df, label=columns[idx+1])
axes[idx].set_xlabel('Time')
axes[idx].set_ylabel(columns[idx+1])
axes[idx].set_title(columns[idx+1])
fig.tight_layout()
plt.plot()以上のファイルを用意して、jupyterlab上でmain()を呼び出せば、1週ごとの棒グラフが表示されると思います。
私も詰まったところが、pythonファイルを更新すると、モジュールを読み込む際は、「カーネルを再起動するか、import libを使う」必要があります。詳しくは以下のサイトに記載されているので、ご参考いただけると幸いです。
【Python】Jupyter notebookを使うときに守るべきPythonの作法2選
これで10項目のtwitterデータをグラフ化できました。データのトレンド表示はデータ分析の初歩なので、ぜひグラフ化にチャレンジしてみてください。
次回は、twitter_dfを使用してグラフ化したあと、もう少し詳細な解析をしていく予定です。
また、今後の分析内容としては
- 評価基準の設定およびその可視化
- 統計学とTwitterデータをからめる
などを予定しています。乞うご期待ください。それでは、よいPythonライフを!!
関連する次の投稿は以下です。ご覧いただけると幸いです。



[…] [Docker, Python] Twitterアナリティクスを分析してみた(③グラフ化編) | バランブログ より: 2020年10月26日 12:57 PM […]