
【Python-Streamlit, Docker】kaggle-タイタニックの機械学習Webアプリを実装する(その5)
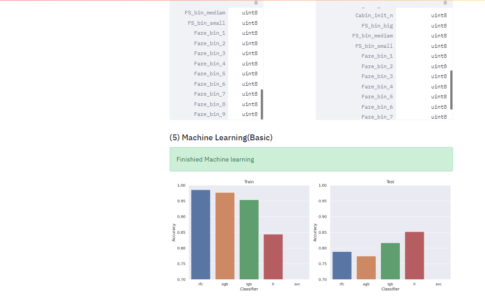
前回までで、kaggleデータを取得して機械学習の訓練用データとテストデータを作成しました。今回は、そのデータを使用して簡単な分類学習を実施していき、その結果をStreamlitで表示していきます。 1. Streaml...
 python
python前回までで、kaggleデータを取得して機械学習の訓練用データとテストデータを作成しました。今回は、そのデータを使用して簡単な分類学習を実施していき、その結果をStreamlitで表示していきます。 1. Streaml...
 python
python今回はkaggleデータを取得して、機械学習の訓練用データと検証データを作成します。 1. Streamlitとは 詳しくは、Streamlitで確認してみてください。 大まかな内容は PythonコードのみでWebアプ...
 python
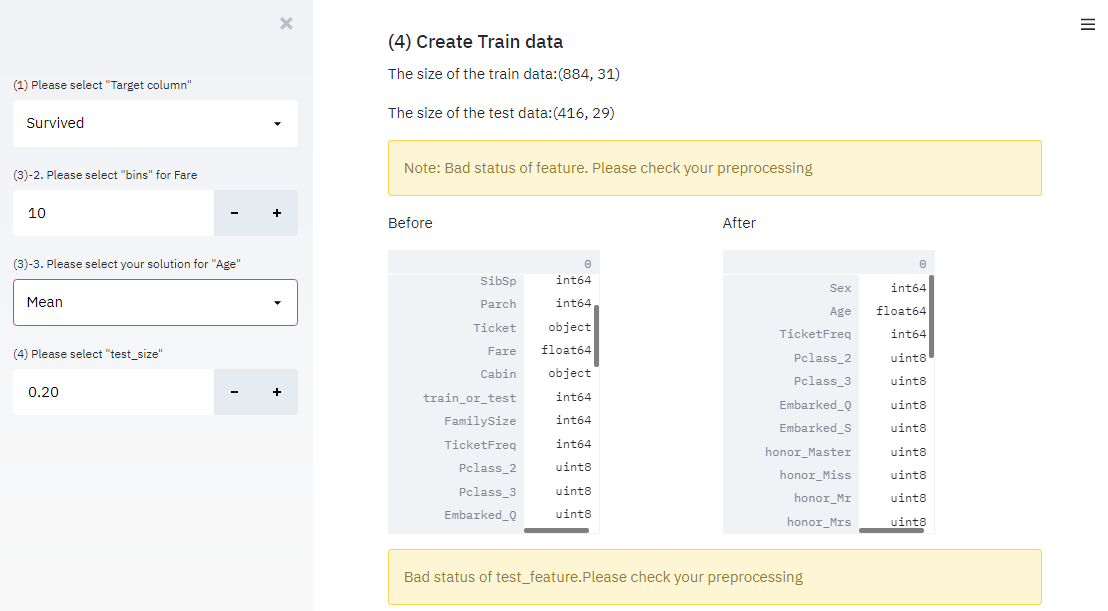
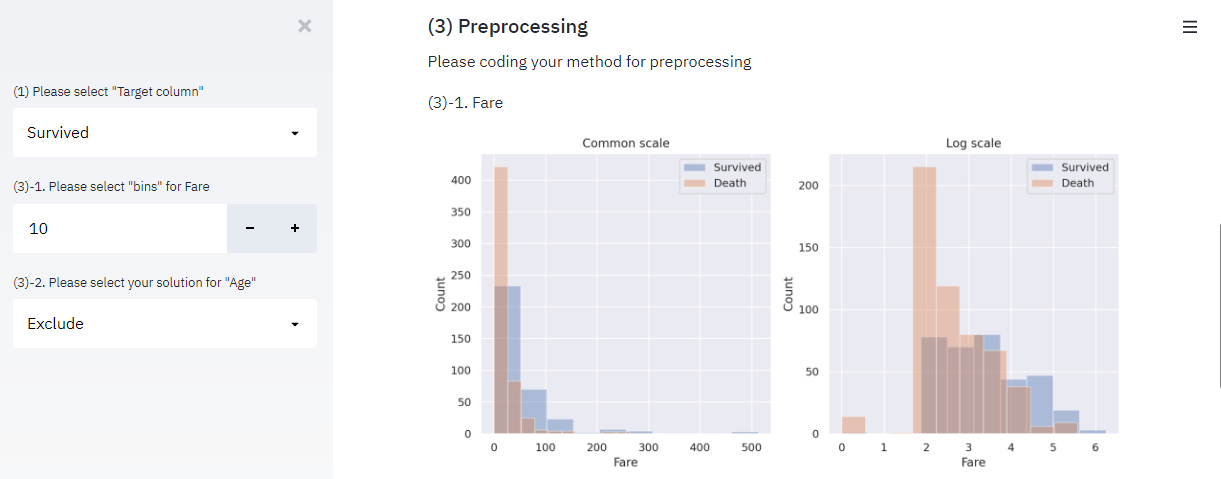
python今回は、kaggleのタイタニックデータを用いて、機械学習のWebアプリをDockerおよびPython-Streamlitで実装してみたいと思います。 今回は機械学習前のデータ前処理具合を可視化していきたいと思います。...
 python
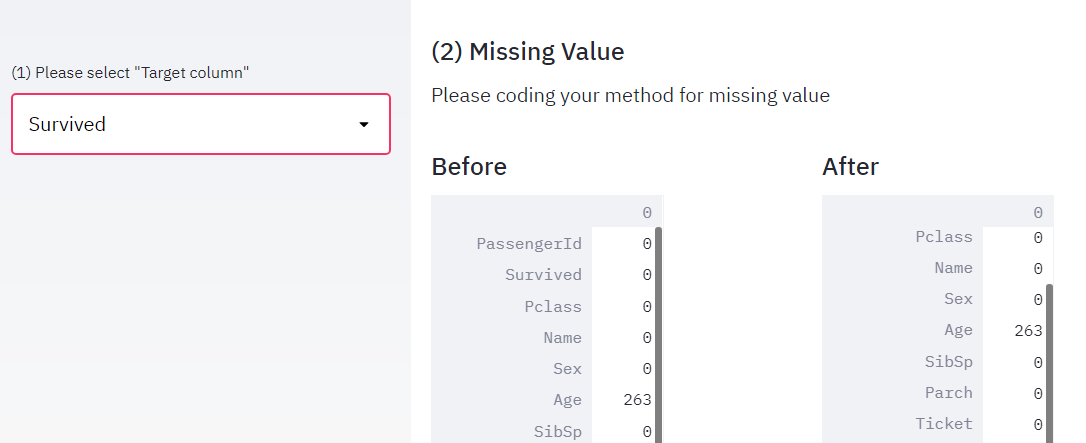
python今回は、kaggleのタイタニックデータを用いて、機械学習のWebアプリをDockerおよびPython-Streamlitで実装してみたいと思います。 今回はkaggleデータを取得して、欠損値の処理前後のデータ数を表...
 python
python今回は、kaggleのタイタニックデータを用いて、機械学習のWebアプリをDockerおよびPython-Streamlitで実装してみたいと思います。 今回はkaggleデータを取得して、Webアプリ上にデータ数を表示...
SQLThe-Japan-DataScientist-SocietyのSQL編を解き終わったので、回答する際に閲覧したサイトを忘備録として、まとめておきます。 1. データサイエンス100本ノック概要 以下、The-Japan...
dockerThe-Japan-DataScientist-SocietyのPython編を解き終わったので、回答する際に閲覧したサイトを忘備録として、まとめておきます。 1. データサイエンス100本ノック概要 以下、The-Ja...
 python
python冬休み中にSIGNATEさん主催のBignner向けのコンペがあったので勉強がてら参加してみました。 結果からご報告させていただくと、参加者数582人中12位でした。未経験・30代から始めた自分としては、満足する結果でし...
 docker
dockerDockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。今回は、忘備録を兼ねて、t値の意味とpython sk-lea...
 docker
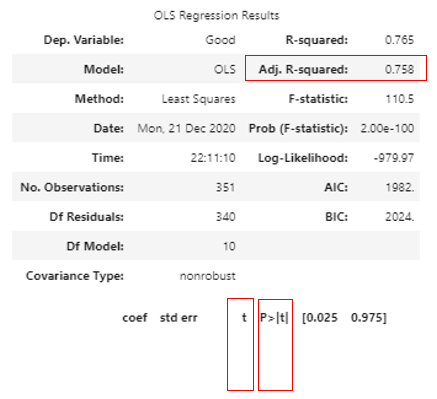
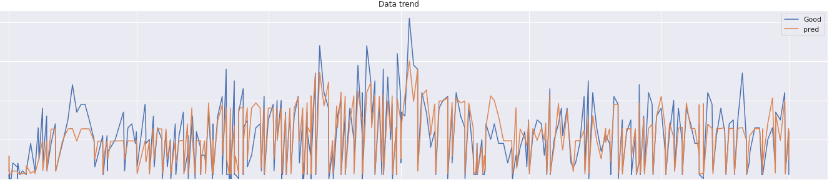
dockerDockerで環境構築、jupyterlabおよびPythonを使用して、Twitter機能の一つであるTwitterアナリティクスのデータを分析しています。前回はsk-learnで重回帰分析を行いましたが、今回はSta...