

Pythonのコードを書いていると、コードが長くなったり、機能が散らばったりしていて、見にくくなっていることはありませんか?
本記事は、サンプルコードを用いて、自分用の関数を作成する方法を記載しています。
本記事を読むと、
- 自分で関数を作成する
- コードを機能別に分ける
ができるようになります。ぜひ、
▼ Contents
0. 使用環境
- OS: Windows10 Pro
- Visual Studio Code: Version 1.47.0
- Python: Version 3.7.6 (64bit)
- pandas: Version 1.0.1
1. データ解析の全体図
本記事のデータサイエンスの紹介範囲を示します。
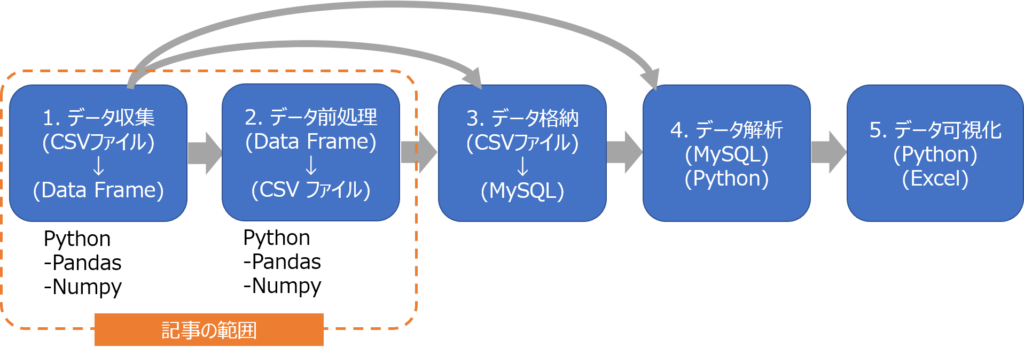
データサイエンスは主に5つのステージがあります。(図のようにステージを飛ばす場合もあります。図は一例です。)
- データ収集(データを集めて処理できる準備をする)
- データの前処理(データを格納もしくはデータを解析しやすいようにデータ配列を適切にする)
- データ格納(データを格納しておく)
- データ解析(実際のデータを用いてデータ分析・解析する)
- データ可視化(解析結果の意味がわかりやすいように可視化する)
本記事では、すべてのステージをカバーする関数の作成となります。
それでは、やっていきましょう。
2. 関数の作成方法
2.1 サンプルコード
サンプルコードは以下です。今回は、
- リストにデータを追加する関数
- リストに格納されているデータを結合する関数
- CSVファイルとして保存する関数
を作成していきます。
import pandas as pd
from pathlib2 import Path
P = Path('/work/csv_file')
FILE_NAME = '**/*.csv'
CSV_FILES = P.glob(FILE_NAME)
COLUMN_NAMES = pd.read_csv('/work/column_name1.csv').columns.tolist()
MONTH = "2020-08"
OUTPUT = "006"
LIST = []
def main():
for name in COLUMN_NAMES:
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)
df = pd.concat(LIST, axis=1)
output_name = 'example_{0}_{1}_{2}.csv'.format(OUTPUT, MONTH, name)
df.to_csv(output_name, encoding="utf-8")
if __name__ == '__main__':
main()なお、本記事で使用するCSVが格納されているフォルダ構成例の全体図を見ていきましょう。今回はworkフォルダー直下にPythonファイルとカラム名用のCSVファイル”column_name1.csv”を用意しています。
“pathlib”ライブラリやデータスライス方法、データ結合方法が不明な方は以下のブログを見ていただけると理解がスムーズかと思います。

2.2 関数化の方法
まずは、リストにデータを追加する関数です。サンプルコード内でリストにデータを追加するコードは以下です。その中で、”for file in CSV_FILES”以下を関数化してみます。
for name in COLUMN_NAMES:
""" --- 以下を関数化する --- """
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)関数化するには、以下の順序で検討します
- 関数の名前を定義します。
- 関数内の変数を確認します。
- 関数用の変数を”def”で定義して、main関数に関数を記載する。
まず、関数の名前を定義しますが、今回はリストにデータを追加関数なので、”list_append”としておきます。そして、関数内の変数を確認します。関数内の変数は”file”と”name”です。
ただし、”file”はfor文により生成されますが、”name”は関数内で定義できなさそうです。このとき、関数に変数を代入するため、関数への引数を定義します。
今回であれば、関数内に”name”を渡せば、うまくいきそうです。上記をもとに、関数を定義してみましょう。以下のようになります。
def list_append(name):
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)そして、最後にmain関数にこの”list_append”関数を記載します。このとき、関数に代入する変数”name”を渡すことを忘れないようにしましょう。
def list_append(name):
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)
def main():
for name in COLUMN_NAMES:
""" 新しい関数list_appendを読み込む """
list_append(name)
df = pd.concat(LIST, axis=1)
output_name = 'example_{0}_{1}_{2}.csv'.format(OUTPUT, MONTH, name)
df.to_csv(output_name, encoding="utf-8")では、同様に
- リストに格納されているデータを結合する関数
- CSVファイルとして保存する関数
を作成してみましょう!(データ結合は”return”でデータフレームをmain関数に返す必要があることに注意!)
関数化すると、サンプルコードは以下のようになると思います。
import pandas as pd
from pathlib2 import Path
P = Path('/work/csv_file')
FILE_NAME = '**/*.csv'
CSV_FILES = P.glob(FILE_NAME)
COLUMN_NAMES = pd.read_csv('/work/column_name1.csv', encoding="utf-8").columns.tolist()
MONTH = "2020-08"
OUTPUT = "006"
LIST = []
def list_append(name):
""" 一括でフォルダ内のcsv読込=>データ抽出 """
for file in CSV_FILES:
df1 = pd.read_csv(file, names=COLUMN_NAMES)
df2 = df1.loc[:, name]
LIST.append(df2)
def list_concat():
""" 格納されたデータを結合する """
return pd.concat(LIST, axis=1)
def output_csv(name, df):
output_name = 'example_{0}_{1}_{2}.csv'.format(OUTPUT, MONTH, name)
df.to_csv(output_name, index=False, encoding="utf-8")
def main():
for name in COLUMN_NAMES:
list_append(name)
df = list_concat()
output_csv(name, df)
if __name__ == '__main__':
main()“main”関数がスッキリしました。また、関数ごとに目的がわかりやすく記載されているため、機能を追加するときにも、関数ごとに追加できるので便利ですね。
コードを書く際は関数化することで、自分だけでなく、他の人が見る際にもコードがわかりやすくなるため、ぜひ書き方をマスターしてもらえると幸いです。
3. まとめ
今回の記事は、pythonコードの関数化に関数方法をまとめました。
関数化することで、
- “main”関数がスッキリする。
- 関数ごとに目的がわかりやすく記載できる
- 自分だけでなく、他の人が見る際にもコードがわかりやすくなる
と、メリットばかりなのでぜひ使い方をマスターしてください!
次回からは、業務の自動化・効率化に向けた自動動作プログラミングなどを作成していきます。
乞うご期待!
それでは、良いpythonライフを!




コメントを残す